
There is quite a wealth of ODBC database connectivity available for OS/2 - ranging from standalone "local" databases, to servers which run on OS/2, to clients which allow OS/2 applications to access data on servers that run on other platforms. In this part we broaden our view somewhat to look at ODBC drivers and the databases behind the drivers. We will try and cover all the ODBC drivers and associated databases that are available now for OS/2, either through open source, commercial channels, or readily available through eBay as used software.
In this part we will discuss each of the ODBC drivers - where to get it and how to install and configure it. For those ODBC drivers that connect to OS/2 based servers or "local" databases we will discuss the database itself: where to get it, how to install it, and the major features of the database. And since there are some valuable and very powerful WinOS2 applications we will also discuss how to install ODBC for WinOS2 where appropriate.
It is in this part that we will see the broad spectrum of ODBC/database interfaces - everything from ODBC connecting directly to the database, to ODBC connecting to a client that connects to a database, to the ODBC driver being the database itself. Also we will see databases that range from being simplistic SQL interfaces to file systems, to full featured commercial systems that rival what is available on any platform. But before we can discuss and compare ODBC drivers and databases, we need to understand some common features that differentiate databases and that make using them easier.
Because of the size Part 3, it will be split between this month and next month's issues. This month we briefly describe many of the common features of databases, look at installing ODBC drivers, and look at ODBC drivers/databases for dBase, text files, Btrieve/Pervasive.SQL, and Watcom SQL. Next month we will complete Part 3 by looking at DB2/2, MS SQL Server, PostgreSQL, Oracle, Sybase SQL Anywhere, Sybase System 10, and possibly mySQL and miniSQL. Missing in action is Informix, Ingres, SolidServer, Gupta SQLBase, and MicroDecisionware Database Gateway - I have not been able to get any information about those databases on OS/2.
As databases have evolved over the years a number of features have become standard, or rather common. Although many of these features are common to a number of databases, no database has all the features. The features that you need in a database are determined by the use you are going to make of the database. For example, if you are selecting a database to store and serve up documents to a web server, you will be concerned with how fast you can connect to the database and how fast the database can serve up the data; but you will not be as concerned with online backup or roll-forward recovery. If you are selecting a database that will be accessed by users from around the country or world, you need strong client support, etc.
In this section we list and describe common features, plus some features that I have found over the years to be especially useful.
Database security means protecting objects and structures in the database from users that shouldn't access them while allowing access to those users with the proper needs. User security generally isn't much of a concern for a database being used to serve up web documents since the web server and CGI (Common Gateway Interface - a specification for how web servers can call external programs and how those programs can interface to the web server) programs will generally handle the security and access control issues.
User security means the database requires a user identification in order to log into the database; object security means that permissions for viewing, accessing and changing database objects are assigned by user ID.
User security is generally implemented either entirely within the database, or it is integrated into the server's operating system security system. When user security is integrated into the server's operating system, each user that is allowed to log into the database must appear as a user in the operating system's security system. DB2/2 is an example of this type; each user that accesses the database must appear in the User Profile Management system of OS/2. If user security is implemented within the database then user IDs are entered in the database system, and those IDs are separate from the operating system/network's user IDs. In OS/2, user IDs are administered in by the User Profile Manager (UPM) tool - located in the System Setup folder.
Object security means that access to objects is controlled through the granting of permissions to user IDs and/or groups. Database objects in this case mean tables, and if the database supports it: views, triggers, procedures, etc. The "owner" and/or database administrator grants permission to an object. Permissions usually include: select (i.e. read), update, delete, insert, grant, drop (delete meaning to delete a row of data, drop meaning to get rid of the object.)
Most database systems that implement user security also implement object security, but there are exceptions; miniSQL for instance implements only user security where each user is granted read or write access to the database as a whole.
Views are objects that look and (mostly) act like tables. A view can be built from a single table or multiple tables joined together. A view can include all the column(s) and rows of the table(s), or a subset of column(s) and/or rows. A view is basically a select statement that is assigned a name. For example to create a view of the voters table that only contains the electors (the voters) who reside on Maple street you could use the SQL statement
create view vote1 as select * from voters where street_name = `Maple'
which would create a view called vote1.
The view does not really exist until it is used - the select statement is executed automatically (materialized) whenever the view is referenced. This way the data always resides in the constituent tables and is always current.
Views are used for two purposes:
Permissions to look at (select) and update tables are generally granted to the entire table, i.e. all rows and all columns. Views are a mechanism that is used to allow some users to only see or update a subset of columns in a table, or a subset of rows in a table. To this end a view can be created which contains a subset of data, and permissions are granted to the view which are different than the table itself.
In large, fully normalized databases,c some queries can become quite complex. (Normalizing is a process of designing the tables in a database to prevent data duplication and to insure that relationships in the data are accurate and unique. Generally the more "normalized" a database is the more tables the data is distributed among.) Queries can not only become large, but complex enough that an incorrectly structured query can generate results that look appropriate but are actually incorrect. Views are a way of pre-generating and packaging common queries.
Some databases support the creation of views but do not allow the data represented in the view to be updated, others allow updates to views but are rather restrictive about how complex the view can be and still be "updateable".
Comments are text descriptions which can be assigned to database objects, such as views, tables, columns in a table, etc. with the SQL command COMMENT ON object. Various ODBC functions will return the comments associated with database objects when listing those objects.
Comments are used to help document the structure of a database, both for the database administrator and for users of the database. The figure below shows creating a comment on the table department and listing the tables in the database along with their comments.
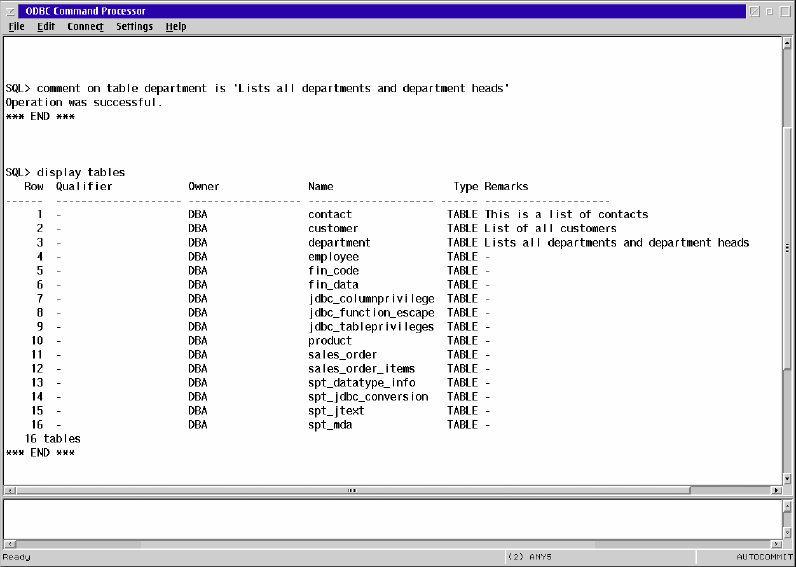
(This section is mostly quoted from the Microsoft ODBC 3.0 Programmer's Reference, Volume 1, and SDK Guide and from the PostgreSQL User Manual)
A transaction is a unit of work that is done as a single, atomic operation; that is the operation succeeds or fails as a whole. For example, consider transferring money from one bank account to another. This involves two steps: withdrawing the money from one account and depositing it in the second. It is important that both steps either succeed or fail as a unit - it is not acceptable for one step to succeed and the other to fail. A database that supports transactions is able to guarantee this.
Transactions can be completed by either being committed or rolled back. When a transaction is committed the changes made are permanently saved; when rolled back the changes are discarded and all the data returns to the state it was in before the transaction started.
A single transaction can encompass multiple database operations that occur at different times. If other transactions had complete access to the intermediate results the transactions might interfere with each other. For example, suppose one transaction inserts a row, a second transaction reads that row, and the first transaction is rolled back so the row disappears. The second transaction now has a row that does not exist.
To solve this problem there are various schemes to isolate transactions from each other. Transaction isolation is generally implemented by locking rows, which precludes more than one transaction from using the same row at the same time. Sometimes however transaction isolation is implemented by locking blocks of rows, or an entire table. With increased transaction isolation comes reduced concurrency, or the ability of two transactions to use the same data at the same time.
The ANSI/ISO SQL standard and ODBC standard defines 4 levels of transaction isolation in terms of three phenomena that must be prevented between concurrent transactions. These undesirable phenomena are:
The 4 isolation levels and corresponding behaviors are describe below.
|
Mode |
Dirty Read | Non-repeatable Read | Phantom Read |
|---|---|---|---|
| Read Uncommitted | Possible | Possible | Possible |
| Read Committed | Not possible | Possible | Possible |
| Repeatable Read |
Not possible |
Not possible |
Possible |
|
Serializable |
Not possible |
Not possible |
Not possible |
The ODBC standard does not specify how a database must implement transaction isolations levels - but it does offer suggested implementation of the isolation levels.
|
Isolation Level |
Possible Implementation |
|---|---|
|
Read uncommitted |
Transactions are not isolated from each other.Transactions running at Read Uncommitted level are usually read only to prevent adversely affecting other transactions. |
|
Read committed |
The transaction waits until rows write locked by other transactions are unlocked; this prevents it from reading any "dirty" rows. |
|
Repeatable read |
The transaction waits until rows write locked by other transactions are unlocked; it holds read locks on all rows returned to the application and write locks on all rows it inserts, updates or deletes. |
|
Serializable |
A transaction waits until rows write locked by other transactions are unlocked; it holds either a read lock (if it only reads data) or a write lock (if it can update data) on the range of rows if affects. |
When multiple people are using a database that has transaction isolation it is possible for a deadlock situation to arise where two users are each in a transaction that is waiting on the other user to free a table or resource. Deadlock resolution is where the database will recognize a deadlock situation and resolve it; usually by rolling back one of the user's transaction.
Transactions, isolation and deadlock resolution are important issues when selecting a database where multiple users are going to be updating data at the same time. For read-only type applications these features are not so important.
Before any data or object in a database can be accessed, an application must "connect" to the database. The connect process usually entails both the client and server allocating memory and performing other setup tasks which takes some amount of time.
Generally the connection speed - that is how long it takes to connect to a database - is relatively unimportant. The exception to this is an application which makes many short term connections, for example web based applications, or one which takes an excessive amount of time to connect, e.g. Oracle 8i on Windows 2000. One way of handling the connect time issue for web based applications is to have a "connection manager" which opens and monitors multiple database connections, distributing those connections to a web page/application as needed. The downside of a connection manager is that someone is always connected to the database - which increases the importance of online backup.
We will rate each database for connect speed in terms of fast, average, and slow.
Online backup means the ability to backup the database while it is being used, and the ability to restore to the point of the backup. The alternative to online backup is restricting users from accessing the database while doing backup - or not being able to backup the database while users are connected.
Having online backup capability allows for more uptime with a database since users don't have to be disconnected from the database in order to do a backup.
SQL is the method of interfacing with a database. For me the strength of a database's implementation of SQL is one of the most important criteria for choosing a database. While SQL is a standardized language, the language has gone through a number of revisions, namely: SQL89, SQL92 and SQL3. Each database conforms to a lesser or greater extent to one or more of the standards. Most databases released in the last half of the 1990 conform to some extent to the SQL92 standard, while the older databases conform to the SQL89 standard.
In addition to how well a database does or does not conform to an SQL standard, most databases offer "enhancements" or additional features to SQL that are not included in the standard. These enhancements range from the "nice to have" category to "how could I ever live without this" absolute necessities. We will point out some of these enhancements in each database's section below.
The job of transforming an SQL statement into a result set of data falls to the query optimizer. This part of the database examines the SQL statement and the layout of the table(s) involved - including the distribution of the data in the table(s) - in order to arrive at the best way to retrieve the data. The way the optimizer chooses to retrieve the data is called the access plan. The more sophisticated query optimizers are "cost based", meaning that the optimizer judges between alternative access plans based on estimates of the amount of time and resources (cpu cycles, disk accesses and speed, memory requirements) each would use to get the data and picks the best one. Some of these more sophisticated query optimizers can also recognize inefficient SQL statements and will re-write the SQL statement into something more efficient as part of the optimization process.
How well a database conforms to a particular version of the SQL standard may or may not be important to you. Close conformance to the SQL language standard can help you be able to move from one database vendor to another should the need arise. On the other hand, taking advantage of SQL enhancements tends to lock you into that vendor's database.
SQL execution speed can be very important with large amounts of data. It is not unusual for complex queries on large amounts of data to take minutes to run. If you are routinely working with large amounts of data, SQL execute speed will be very important.
Triggers are events that happen during SQL processing to which you can attach code. The events generally are before update, after update, before delete, after delete, before insert, after insert; and sometimes before and after a statement and before and after a user connects. The code that can be attached to the trigger "event" ranges from plain old SQL, to some procedural language peculiar to that database, to external procedures contained in a DLL or separate programs.
Triggers are generally used to perform data validation and extra data processing. Since the trigger is defined at the database it is executed every time any application or person "triggers" the event, making it much more robust and easier to program than trying to put that logic in all applications that access the database.
Triggers become more important with multiple users and multiple applications accessing a database; with a single application such as a web server, or with a single user, triggers assume less importance.
Procedures are SQL statement(s) that are stored in the database and executed at the database server. Since the procedure is executed at the database server it can sometimes be much more efficient than the same set of statements executed from the client machine - mainly because the data used by the statements does not have to travel back and forth between the server and the client for each statement in the procedure.
Many databases allow procedures to be assigned access rights different than the rights of the tables and other database objects that are used in the procedure. This can be used, like views, to enhance security or work around security issues. For instance a procedure could be created to access sensitive payroll information returning only that information deemed appropriate to users, and user could be granted rights to the procedure but not to the underlying tables.
User Defined Functions (UDF) is the name IBM gives to procedures in DB2/2, in an attempt to marry the concept of procedures and "object-ness" into a single concept. (Some relational databases have been adding features to try and address object oriented concepts in a relational database. These features include user defined data types, user functions, etc.)
Referential integrity means linking together related tables by common fields in order to keep the tables in sync. For instance a database may contain a table which stores personal information such as name, employee number, etc. The same database may also contain a table listing departments and department heads, where the department head links back to the personal table by the employee number. Referential integrity can be used to insure that no employee number is entered as a department head unless that employee number already exists in the personal table.
One step up from simply preventing the entry or change of data in one table that doesn't conform to another table, is correctly handling changes to linked information between tables. For instance in our example above, if an employee who is also a manager is terminated, what happens to the departments table when the employee is deleted from personnel table? The more complete referential integrity implementations give the database administrator the option of preventing the deletion, allowing the deletion and also "cascading" that deletion to the department table where the linked row is also deleted, or leaving the row in the department table but changing the linked value (employee number) to null.
Referential integrity is very important for maintaining data integrity and consistency.
Large table support means the database can handle a single table which requires more than 2 GB of disk storage. This is, or rather was, an issue because of the limitation OS/2 and other operating systems used to have where the maximum size of a hard disk partition could not exceed 2 GB - hence no single table could exceed 2 GB since tables resided in a single partition. Now OS/2 (and most other operating systems) have increased the 2 GB maximum hard disk partition size which increased the maximum table size. But before that happened some database vendors came out with enhancements which allowed a single table to span multiple hard drive partitions.
A side benefit to having a single table span multiple partitions is increased performance. A single table that is accessed by many users can be split among multiple physical hard drives, thereby reducing hard drive contention: two hard drives can be seeking data in the same table at the same time for different users.
Somewhat related to maximum table size is the maximum row size; but where maximum table size addresses how many rows are possible (or rather how much storage space is consumed by multiple rows) maximum row size addresses how much information you can stuff into a single row. This results from the combination of the maximum number of columns that can be defined for a table, and the size of each column.
Columns can be divided into two types: blob and non-blob. Blob (Binary Large OBjects) type columns can store large amounts of data (the limit usually is 32k, 64k or 2 GB) in a single column of a single row. Two examples are memo fields and picture fields. Non-blob type columns are the traditional column types such as integer, date, time, decimal and character which store relatively small amounts of data in a single column for a single row.
Most databases store the data for all the non-blob type columns for a row together in a single "block". A single "block" of storage can hold multiple rows but no single row spans more than one block. If two rows are stored in a single block and one of the rows increases in size because of changes to that row's data so that both rows exceed the block size, the changed row is moved to its own block and its former space in the original block is unused. This is one of the reasons why database files compress so well.
Since memory storage block size is set in OS/2 (and all other Intel based operating systems) at 4k, a single database row could not traditionally exceed more than 4k of storage. Some databases, e.g. DB2/2 v 6, divorce the database "block" from the operating system block and allow a block size to be declared when the table is defined. Increasing the declared block size allows more non-blob data to be stored in a single row.
Replication is a feature which allows copies of the same data to be stored in multiple databases. Replication is usually used for off-line users that need a copy of the data to work with while they are away from the office, and for performance in order to reduce network accesses for users that are located some distance from the database server.
Replication takes many forms, but the most basic features are:
Distributed data is somewhat like replication in that data resides on multiple databases, but unlike replication where the copies of the data resides on multiple databases, with distributed data one copy of the data is spread among multiple databases. For example the personnel table might be on a database at headquarters while each regional office has its own department table.
Distributing data requires transactions to also be distributed. Meaning that the transaction must be able to work as a whole on tables located on different databases. Using the referential integrity example above, if the row was deleted from the personnel table at headquarters then the delete must cascade to the appropriate department table located at the outlying office database.
Heterogeneous data access is one step up from distributed data transactions - where distributed data transactions take place on separate machines but with the same vendor's database, heterogeneous data access allows data to be spread amongst multiple machines and on different vendor's databases.
The user connects and issues SQL statements to a single database and that database does what is necessary to retrieve and manipulate data on the different databases, masking the differences (as much as possible) between SQL dialects and operations of the various databases.
The surprising thing about this feature is the extremes in products where you will find it. In all databases except Microsoft Access, this feature is the very top of the line of that vendor's product. Yet with cheapo MS Access, including version 2.0 which runs on WinOS/2 you get that capability.
Now that we have laid the groundwork necessary to allow us to discuss and compare individual databases, we need to spend a moment talking about ODBC database drivers before we dive into each individual driver and database.
ODBC drivers come from three sources:
While Visigenic once made ODBC drivers I have not been able to locate any of their drivers other than their DB2/2 driver. Visigenic was bought by Borland which took over some of their products and seems to have dissolved the company.
Intersolv makes (made) some very high quality database drivers for OS/2 but refuses to sell those drivers to the public. In addition they have not kept up the OS/2 versions of their driver with the versions they release for Window and Unix. But while Intersolv (now called Merant) will not sell their drivers to the public the drivers are readily available from various sources, mainly:
The drivers that are bundled with other packages generally have very limited usefulness when used with other applications. The driver somehow recognizes what application is using it, and if you use it with something other than what it is bundled with it repeatedly throws up an "annoyware" type banner instructing you to purchase the product (ha - as if you could.)
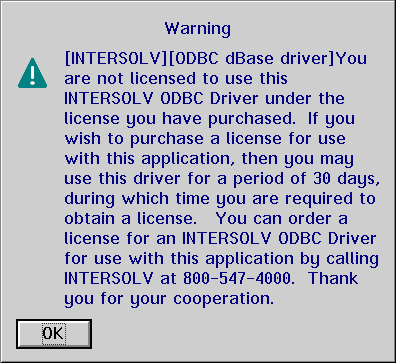
While the annoyware message makes the Intersolv drivers less than pleasant to use with existing applications, writing your own application is another story; the annoyware type banner only appears on PM based applications, not text based or detached programs. If you are writing your own application there are ways around that; for instance the ODBC Command Processor uses named pipes to communicate with a separate detached process that actually calls the ODBC drivers, thereby bypassing the Intersolv "you can't buy this - we will make your life miserable" madness. Developing ODBC applications will be covered in Part 4.
The fact that Intersolv drivers are older versions really isn't much of an issue, especially since you can't pay for them. Most OS/2 applications are written for ODBC v 2 or 2.5 drivers because that was/is the predominate version of driver available. And there is not that much difference in features/functions between ODBC version 2 and ODBC version 3.
The Intersolv drivers that are available come in two versions: 2.11 and 3.01. The packages that contain the 2.11 drivers contains few drivers that do not appear in the packages containing the 3.01 drivers: MS SQL Server, Gupta SQLBase, MicroDecisionware Database Gateway. (I am using "package" here to mean the zipped file containing the database drivers and ODBC Administrator and Driver Manager.) Likewise the packages containing 3.01 drivers have a Btrieve driver that does not appear in the 2.11 driver package. You may want to get and install drivers from both packages; ODBC Database Drivers of different versions can coexist together fine, although you will have to use a Driver Manager that is at least as late a version as the latest driver version. I recommend that you use the 3.01 version driver where one exists.
Intersolv ODBC drivers can be found:
All the above packages include the ODBC Administrator and Driver Manager in the package. In addition the Visigenic ODBC SDK that was included in the Developer Connection #9 CDs includes the Visigenic version of the ODBC Administrator and Driver Manager. The Visigenic and Intersolv Driver Manager and Administrators are interoperable - meaning that either vendor's products will work with all the ODBC drivers and applications out there - except for the iODBC. However the files needed for the Administrator and Driver Manager from each package are different. And the file names for the same drivers are different in each of the packages listed above. (I believe the first two letters of the file name for Intersolv driver denotes which bundle the driver belongs in, and the last two letters denotes the Intersolv version.)
iODBC is an Open Source project to develop an ODBC driver manager for Unix systems. Dirk Ohme ported the driver manager and some database drivers some years ago. The iODBC driver manager appears to not be compatible with most OS/2 ODBC applications. In addition the iODBC administrator does not work with non-iODBC database drivers.
The ODBC Installer is an application that will install the ODBC administrator, driver manager, and database drivers from all the packages above, except the Lotus SmartSuite bundle. It will also install DB2/2, Watcom SQL and Sybase SQL Anywhere 5 database drivers. (I must apologize here to those of you that tried to download this installer from last month's article. I had started the ODBC Installer and thought I would be done by the time that issue was published. Instead it took all month to finish the application).
To use the ODBC Installer unzip it into an unused directory. Then check that
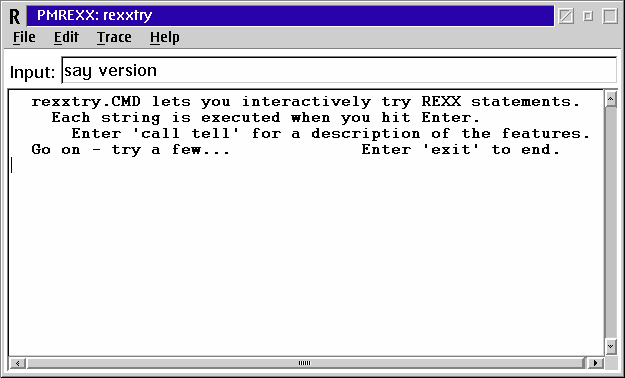
You can check which type of Rexx interpreter you have by opening an OS/2 Command Prompt window and typing pmrexx rexxtry from the prompt. This will bring up a screen as in the figure below. Then type say version and hit Enter. You should see OBJREXX 6.00 18 May 1999 in the window if you have Object Rexx installed.
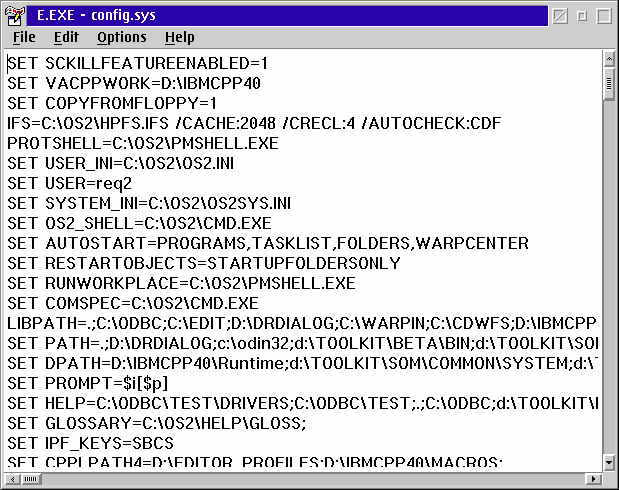
To check the LIBPATH statement in your CONFIG.SYS file - from the same Command Prompt window type e config.sys. This will display the CONFIG.SYS file. In the figure below you can see the characters.; immediately after the equal sign on the line that begins LIBPATH.
If you do not see the .; characters in the LIBPATH statement type them in immediately after the equal sign and save the file. When you save the file you will be prompted to select a file type - select OS/2 Command File.
Once you have done those two steps execute the ODBCINST.EXE file to start the ODBC Installer. You will see the Source page as shown below. Enter the name of the one of the packages mentioned above, e.g. ODBCDEMO.ZIP, DAX11.ZIP, etc. as your source file and press Enter. You can also enter a directory name instead of a file name if the database driver is already unzipped - for example when installing SQL Anywhere. When you press Enter (or click off the entry field) the Installer will search the source file for an ODBC administrator, driver manager and database drivers. It recognizes 23 different database drivers/versions and the administrator and driver manager from all the packages. If the ODBC Installer finds the administrator and driver manager files the check box "Install Administrator & Driver Manager" will be enabled and checked. The drivers that are found are put in a list on the Drivers page for you to select for installing.
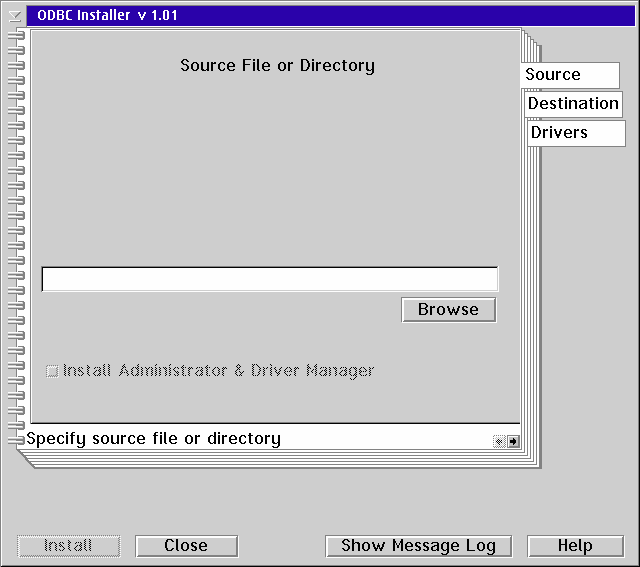
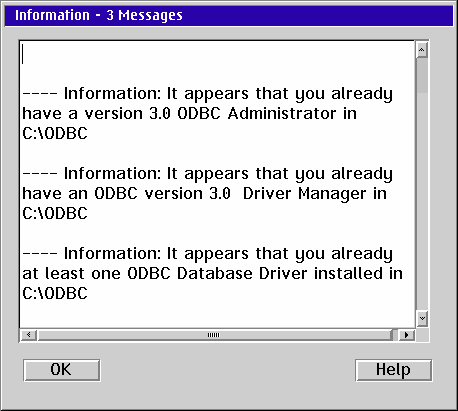
Next click on the Destination page. This page is where you specify the location(s) where the ODBC components are to be installed. If the ODBC Installer finds an existing installation it will set the destinations to the locations of the existing components which you should not change. If you already have ODBC installed you will get a message box telling you what parts of ODBC the Installer found. You can re-display the message(s) by pressing the "Show Message Log" button. If you don't already have ODBC installed you can specify any directories you want for the destinations - however I suggest you use the defaults.
If the directories you specify do not exist the "Create Directories" button is enabled and you will have to create the directories before you can install.
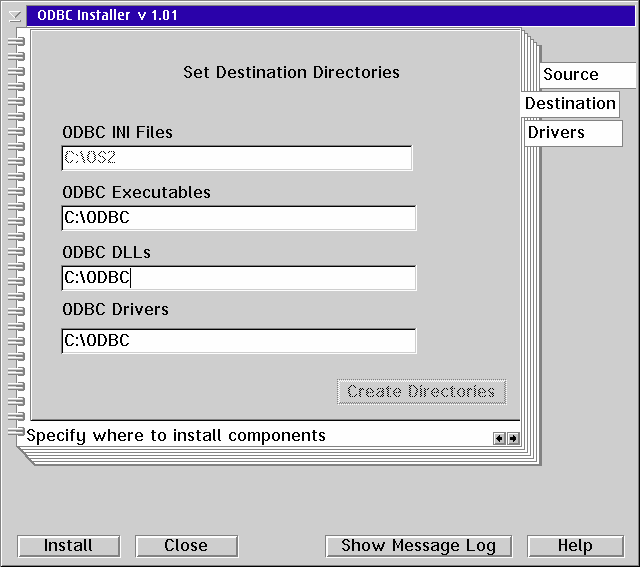
The ODBC INI files - ODBC.INI and ODBCINST.INI - should be installed in the C:\OS2 directory. If the ODBCINST.INI file is found on your system you must use the destination where it was found.
The Drivers page will look different depending on whether you already have database drivers installed or not. If you already have database drivers installed the Driver page will have two minor tabs - one for listing all the drivers already installed and one listing the drivers found in the source file/directory that you can install.
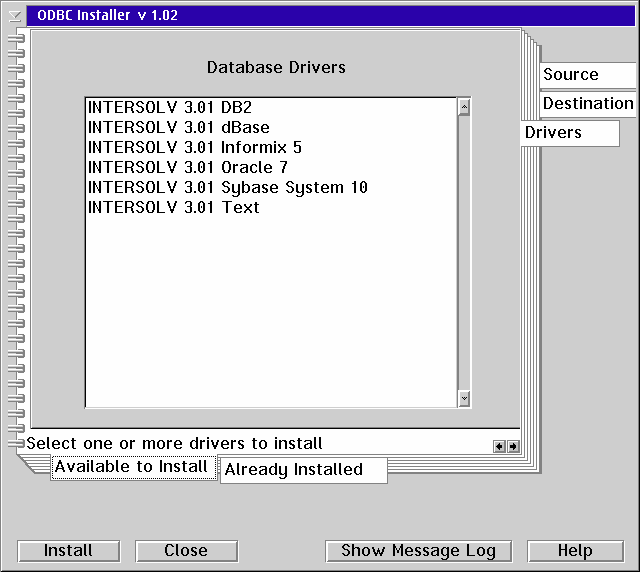
When the destination directories point to existing directories, and you have selected either to install the Administrator & Driver Manager on the Source page or selected one or more drivers on the Drivers page, then you can press the "Install" button.
Installing each of the packages is the same, except for the ODBC3_01-BIN_OS2.ZIP package. If you try and re-install that package you will run against the file CPPOM30.DLL which may not be overwritten. This is because that DLL is apparently used by other applications (at least on my system) so click the "Skip This File" button on the re-install. The only way I could delete CPPOM30.DLL was to boot to a maintenance version of OS/2 and delete it from there.
Btrieve is an old database originally used on Novell Netware operating systems. It was ported to other platforms and the database split from Novell Netware to became a separate company now called Pervasive Software. IBM paid for Btrieve version 6.x to be ported to OS/2 but Btrieve is no longer available for OS/2. At least from Pervasive Software - although strangely enough you can buy the Btrieve manual from the company. I was never able to obtain a copy of Btrieve despite conversations with the company. So what I can describe is what I gleaned from the manual(s) and conversations with a knowledgeable tech support person.
|
Feature |
Description |
|---|---|
| Database Type | Client/Server and local. |
| Security | ? |
| Views | ? |
|
Referential Integrity |
? |
|
Object Comments |
? |
|
Transactions |
Yes |
|
Isolation Levels |
? |
|
Deadlock Resolution |
? |
|
Connect Speed |
? |
|
On Line Backup |
? |
|
SQL Level |
? |
|
Enhancements |
? |
|
Query Optimizer |
? |
|
Triggers |
? |
|
Procedure |
? |
|
Large Table Support |
? |
|
Large Row Support |
? |
|
Replication |
? |
|
Distributed Transactions |
? |
|
Heterogeneous Vendor Access |
? |
Pervasive and Intersolv both released ODBC drivers that allowed ODBC applications to access Btrieve data. Since the Btrieve data structure is so un-SQL like there had to be an intermediate process where the user defined the Btrieve data in SQL type terms, which ended up as three dictionary files: FILE.DDF, FIELD.DDF and INDEX.DDF. With these three files associated with a Btrieve database the ODBC driver could figure out how to access and classify the data.
Pervasive Software merged Btrieve with another product called Scalable SQL into a single database called Pervasive.SQL which was released initially as version 7 and is now at version 2000. The version 7 release included an OS/2 client that accessed Pervasive.SQL data via the Btrieve client. The version 7 client can also access the current Pervasive.SQL 2000 which runs on an NT server.
I have seen Pervasive.SQL 7 on eBay ranging from $45 to $1000. The license arrangement is such that you pay by the number of users that access the server so "theoretically" the client software should be free. If you can't get it from the database administrator of the database you need to connect to, you can purchase a version 7 package to get the OS/2 client.
dBase is an old database application originally published by Ashton Tate. dBase was purchased by Borland some years ago, but before that happened the file format was reverse engineered and became separated from the "database application" to become an almost universal file format for databases. There are a great many applications that can read and write dBase formatted data files, including: MS Excel, Star Office, and Lotus Approach, FoxPro/FoxBase, and Clipper.
The dBase ODBC driver is unusual in that the ODBC driver is also the database engine; the ODBC driver accesses dBase files directly and provides all the database functions. The dBase ODBC driver supports the following SQL statements:
While the dBase ODBC driver makes a very simple database, it is in some ways superior to other databases, e.g. miniSql - certainly the SQL language support is richer. And it is very fast. The size of the driver files is less than 1 MB and without indexes or blob type fields the data is all contained in a single disk file.
|
Feature |
Description |
|---|---|
|
Database Type |
local |
|
Security |
None |
|
Views |
No |
|
Referential Integrity |
No |
|
Object Comments |
No |
|
Transactions |
No |
|
Isolation Levels |
Read Committed |
|
Deadlock Resolution |
No |
|
Connect Speed |
Very fast |
|
On Line Backup |
No |
|
SQL Level |
Subset of SQL89 |
|
Enhancements |
Pack table |
|
Query Optimizer |
No |
|
Triggers |
No |
|
Procedures |
No |
|
Large Table Support |
No |
|
Large Row Support |
No |
|
Replication |
No |
|
Distributed Transactions |
No |
|
Heterogeneous Vendor Access |
No |
|
Data Types |
Binary (blob), Char, Date, Float, General (blob), Logical, Memo(blob), Numeric, Picture(blob) |
The Intersolv text driver is available in the DAX11.ZIP and ODBCDEMO.ZIP packages (Intersolv version 2.11) and Lotus SmartSuite bundle and ODBC3_01-bin_os2.zip packages (Intersolv version 3.01). Support is nonexistent - Intersolv does not support OS/2 products or back version products.
To Install the driver either download the DAX11.ZIP, ODBCDEMO.ZIP or ODBC3_01-BIN_OS2.ZIP file and use the ODBC Installer. Once you have installed the driver you must create a data source before you can access any data. To create a data source start the ODBC Administrator. The ODBC Installer places an icon for the Administrator in the System Setup folder. Press the ADD button.
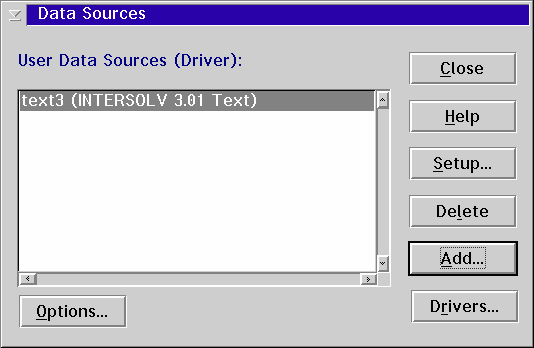
This will bring up a screen shown in the figure below. The screen below is for the version 3.01 driver but the same parameters exist on the 2.11 setup screen. Enter a name for the data source, a description and a directory where the driver should store the tables.
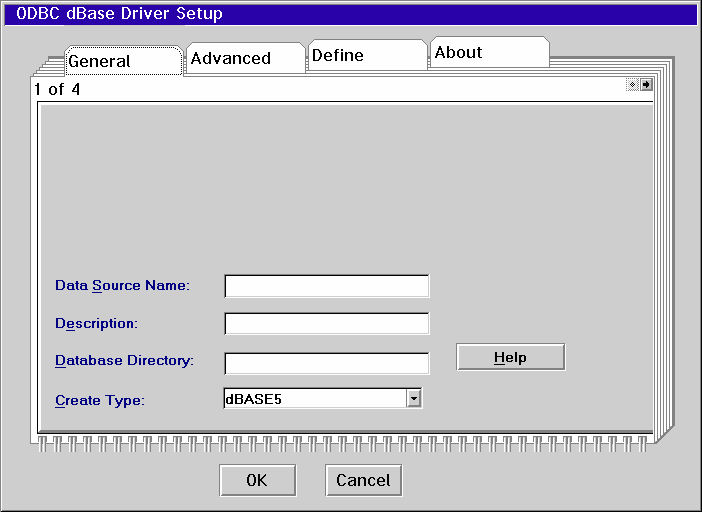
The Intersolv driver treats the Database Directory as the dBase "database". Each individual dBase file (or actually a set of files depending on whether there is an index or not and whether there are blob fields or not) represents a "table" in the "database".
The Advanced tab shows options for using long names as table names and using long path names (long meaning 256 characters, short meaning 128 characters) as the table "qualifier." You can leave this page with the defaults.
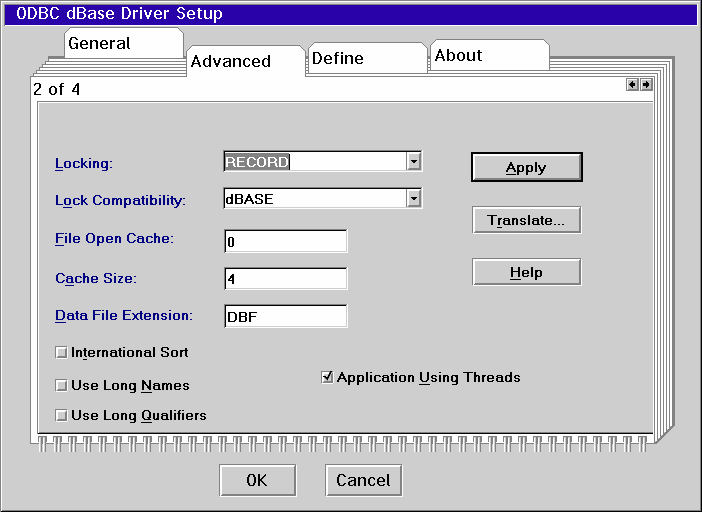
The third page is unique to the version 3.01 driver, and it allows you to specify criteria about indexes for dBase tables that already exist. You can create an index for a dBase table with the create index command.
The dBase ODBC driver makes dBase into a viable SQL type database, albeit a relatively simple one. This driver would be perfect for someone considering a database for serving documents or information to a web server, or other applications where only one user changes data but potentially many users view the data.
The Intersolv Text driver allows text files containing data to be treated as a simple database; the text files we are talking about here are files that contain data, not text files containing letters or documents. Text files are a non-binary way of storing data. Since the file contains only textual characters there must be some way of distinguishing the fields of data in a row, and of distinguishing one row from another. The three most common methods are:
The Intersolv Text ODBC driver supports all three formats of text files, although any character can be substituted for the comma in the first format (CSV). The driver recognizes the following SQL statements:
|
Feature |
Description |
|---|---|
|
Database Type |
local |
|
Security |
None |
|
Views |
No |
|
Referential Integrity |
No |
|
Object Comments |
No |
|
Transactions |
No |
|
Isolation Levels |
Read Committed |
|
Deadlock Resolution |
No |
|
Connect Speed |
Very fast |
|
On Line Backup |
No |
|
SQL Level |
Subset of SQL89 |
|
Enhancements |
None |
|
Query Optimizer |
No |
|
Triggers |
No |
|
Procedures |
No |
|
Large Table Support |
No |
|
Large Row Support |
No |
|
Replication |
No |
|
Distributed Transactions |
No |
|
Heterogeneous Vendor Access |
No |
|
Data Types |
Numeric, Date, Varchar |
The Intersolv text driver is available in the DAX11.ZIP and ODBCDEMO.ZIP packages (Intersolv version 2.11) and Lotus SmartSuite bundle and ODBC3_01-bin_os2.zip packages (Intersolv version 3.01). Support is nonexistent. The driver can be installed with the ODBC Installer. Once it is installed you must create a data source to access data.
Start the ODBC Administrator and press the ADD button. Select the Text driver. When you press OK you will see the following screen. The screen shown is from the version 3.01 driver but the v 2.11 driver has the same parameters.
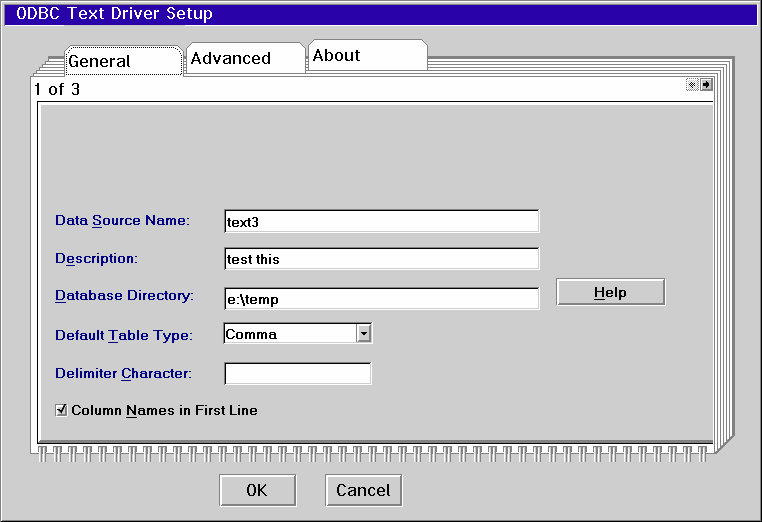
The data source name in the example is text3. The Text driver, like the dBase driver, uses the Database Directory as the "database" with each text file in the directory being a "table".
The Advanced tab shows a page where you can specify if updates and deletes are allowed. This feature is unique to the version 3.01 driver.
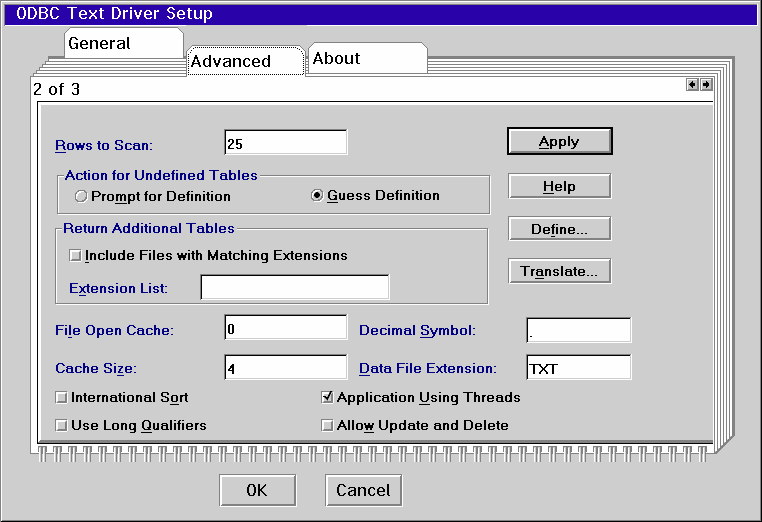
While I cannot imagine much use for the Text ODBC driver as a database, the driver is very useful for importing and exporting text files from an application. For instance using the ODBC Command Processor you can import and export data from any ODBC database using text files. Text files are mainly useful for "normal", meaning non-blob data.
Watcom SQL is a package that has been around since 1988. In version 3.2 Watcom introduced ODBC support and version 4.0 added the TCP/IP protocol as a supported transport. Powersoft bought Watcom and was quickly bought by Sybase. Watcom SQL became Sybase SQL Anywhere - which is covered in the next section.
Watcom SQL exists as a client, server and standalone database engine, all of which run on OS/2, as well as Windows 3.1, Windows NT, Netware and QNX; the client also runs on DOS. Watcom supports ODBC development with header files and libraries that allow the Watcom ODBC driver to be linked directly into an application, bypassing the ODBC driver manager. Or normal ODBC applications can be developed with an ODBC SDK. It is periodically available on eBay in the $15-$35 range. Support is nonexistent.
| Feature | Description |
|---|---|
|
Database Type |
Client/Server and local. |
|
Security |
User and object - user security implemented in the database. |
|
Views |
Views are supported and updateable. |
|
Referential Integrity |
Cascade on delete, change to null, prevent changes |
|
Object Comments |
Yes |
|
Transactions |
Yes |
|
Isolation Levels |
Read Committed, Repeatable Read, Serializable |
|
Deadlock Resolution |
Yes |
|
Connect Speed |
Fast |
|
On Line Backup |
Yes |
|
SQL Level |
SQL92 |
|
SQL Enhancements |
|
|
Query Optimizer |
Some optimizations, does some query re-writes. |
|
Triggers |
Yes - Watcom specific procedural language |
|
Procedure |
Yes - Watcom specific procedural language |
|
Large Table Support |
No - 2 GB max |
|
Large Row Support |
Yes - limited by table size |
|
Replication |
No |
|
Distributed Transactions |
No |
|
Heterogeneous Vendor Access |
No |
|
Data Types |
Char, Varchar, Long Varchar, Binary, Long Binary, Integer, SmallInt, Decimal, Float, Real, date, Time, Timestamp. |
Watcom SQL comes on an install CD and a license diskette. The install CD is the same for all operating systems - the license diskette determines how many users you can have connected. The install CD comes with OS/2, Netware, Windows, and WinNT components for both the server and the client. Installing the server automatically gets you the client - you use the client install for client machines that will connect to the server.
Before you start the install I suggest you create a C:\WINDOWS directory on your hard drive. After the install you can copy the contents of the WINDOWS\SYSTEM directory to your C:\OS2\MDOS\WINOS2\SYSTEM directory if you do not have ODBC - although that will not create ODBC icons in the Windows desktop.
Start the SETUP.EXE program in the SERVER\OS2 directory. Enter the WINDOWS directory you created in step one.
If the install program complains about finding ODBC components already installed tell it to leave those files alone. In the figure below it is confusing the Windows ODBC components it wants to install with the OS/2 ODBC stuff already installed.
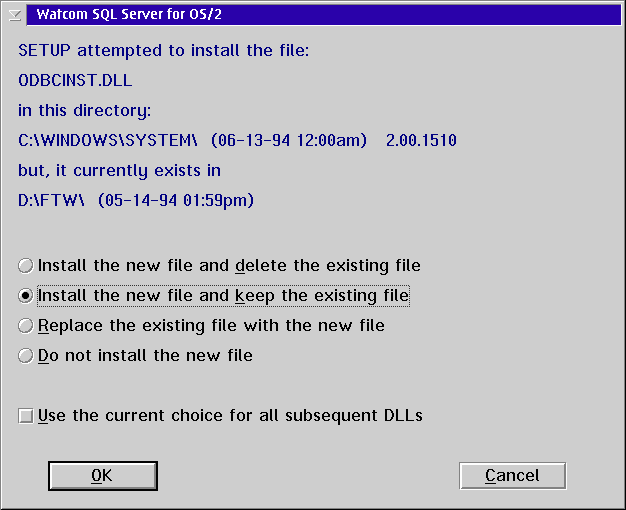
Insert the license diskette at this point. You are almost done with the install.
When you are done with the install go to www.sybase.com (http://www.sybase.com) Sybase web site and find the patches for Watcom SQL. Unfortunately, because of the way the Sybase web site is set up, we cannot provide you with a direct link. You will have to search on WATCOM in the EBU/Updates section. You will need 12 files: 240c.zip - 240f.zip, 2c40c.zip - 2c40f.zip, and 2s40c.zip - 2s40f.zip.
Unzip each file to a temporary directory and run the SETUP.EXE to install the patch. You will occasionally get an error message about not being able to apply a patch or rename a file. Just click on the OK; it doesn't seem to hurt anything. When applying the D patch (e.g. 2s40d.zip) the setup.exe file will crash. Just extract the setup.exe from any other of the downloaded files into the directory and run it.
When you are done with the install you will have a Watcom SQL 4 folder that looks like this. The server program is the Server Sample Database icon.
When you first start the server program it will probably fail when it is trying to start the NetDG protocol. This is a version of NetBios in Watcom SQL version 4 that is compatible with previous versions of Watcom SQL. You can work-around this but not starting the NetDG protocol. To do that you must specify which protocols you want to start when the server starts; note that you must start the NamedPipes protocol if you want to run WinOS2 applications against Watcom SQL 4. The protocols are: NamedPipes, NetBios, TCP/IP, IPX. The -x parameter is used to designate the protocols to start. Change the parameters in the program object to specify which protocols you want to start, being sure to NOT specify NetDG.
When the server starts a monitor window appears which tracks the status of the database.
Watcom provides an install routine for installing its ODBC driver but it did not work correctly. You can install it manually (copying the file and editing the ODBCINST.INI file) or you can use ODBCINST.EXE - which is shown below.
Start ODBCINST.EXE and enter the directory where you installed Watcom SQL. You must enter the OS2 subdirectory as show in the figure below.
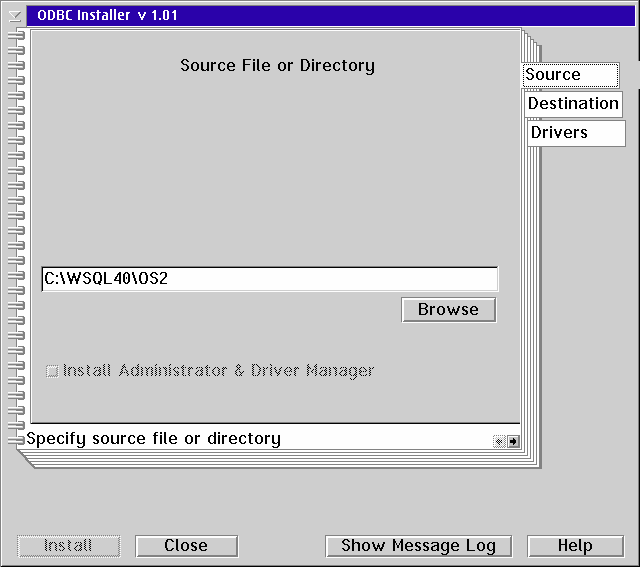
Click on the Drivers page and select the Watcom driver from the Available to Install minor tab. If you do not have any other ODBC drivers installed then your Drivers page won't have any minor tabs - it will just list the drivers you can install.
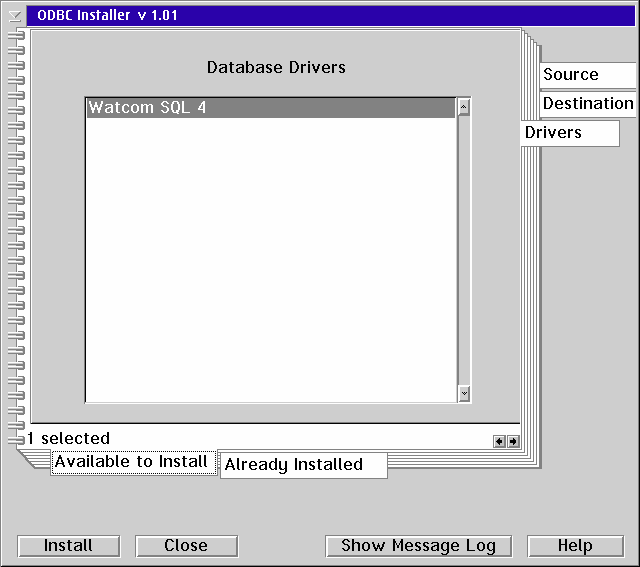
If the driver doesn't appear on the Drivers page then you probably got the directory wrong on the Sources page. Go back to that page and use the Browse button to find the WOD402.DLL file. If you select the file from the Browse button-File Dialog box you'll have to backspace off the file name since the Source only takes directories or Zip files. You just want the directory where that file is found.
Click on the Destinations page and confirm the locations where the files will go. I prefer the use C:\ODBC for all the destinations except the ODBC INI files. That I make C:\OS2.
Press the Install button.
If you don't have the ODBC Administrator and Driver Manager already installed you will have to install them before you can do the next step. To install them get one of the packages mentioned above that contain ODBC drivers and use the ODBCINST.EXE to install the Administrator and Driver Manager.
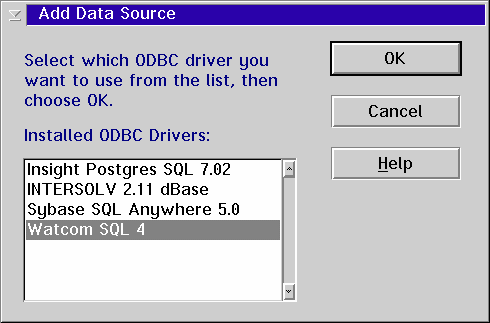
Start the ODBC Administrator (if you used the ODBC Installer to install it the program object will be in the System Setup folder) and press the ADD button.
Select the Watcom driver from the list and press OK.
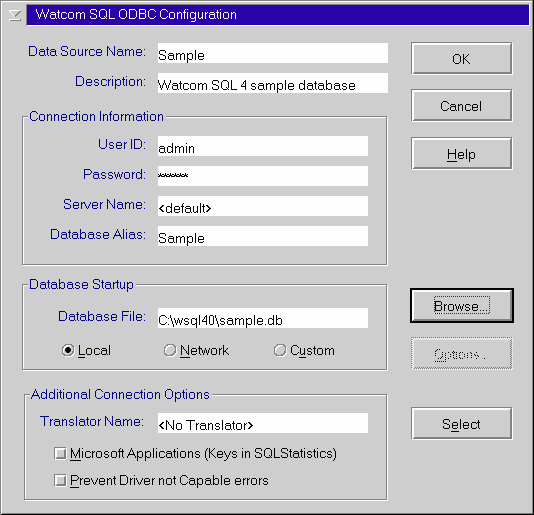
Fill in the Setup screen as show in the figure below.
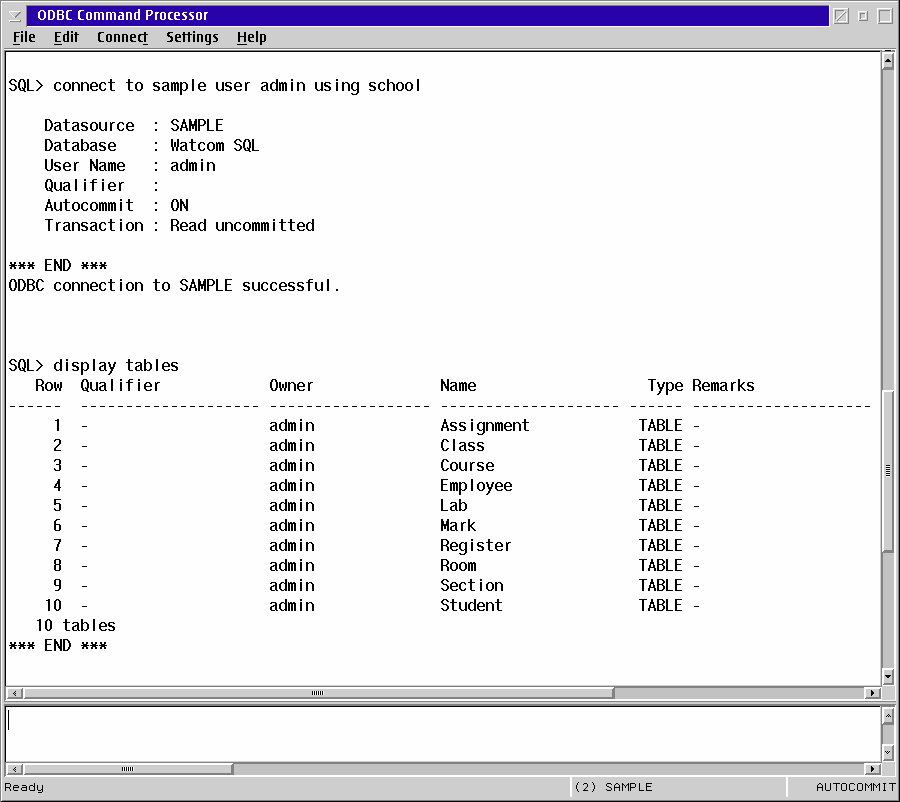
You are now setup in OS/2. If you want you can use the ODBC Command Processor to test the connection. Start the Command Processor (SQL_OS2X.EXE) and type in CONNECT TO Sample USER ADMIN PWD SCHOOL and press Enter. Please note the case of the data source name Sample. You must type on the data source name you want to connect to in the same case as the data source name appears in the ODBC Administrator. If you connect you will see a screen like the figure below. The figure below also shows the DISPLAY TABLES command which lists all the tables in the database.
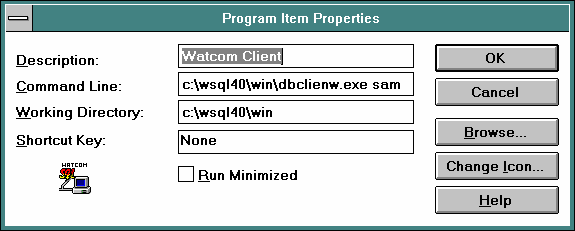
To install Watcom in WinOS2 you must first create a program icon for the Watcom client. Create an icon for the dbclientw.exe program as shown below. Notice (although its partially off the screen in the figure below) that the name of the database (sample) is entered as a parameter to the program.
Now you must create an entry for the Windows ODBC driver in the C:\OS2\MDOS\WINOS2\ODBCINST.INI file. This is a text file, unlike the OS/2 version, so you can edit it with any editor. You must add 4 lines to the ODCBINST.INI file. Add a line to the ODBC Drivers section stating that the driver is installed. Then create a section for the driver and add two lines showing where the files are located.
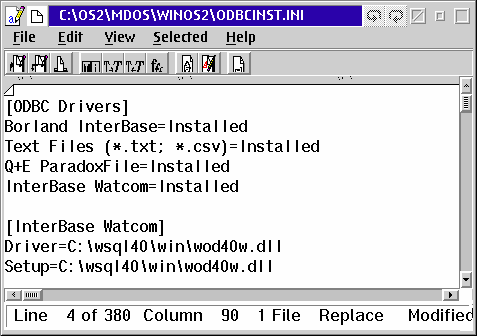
In the figure above the line for the Watcom driver in the ODBC Drivers section is the one that reads:
InterBase Watcom=Installed
The section for the driver is immediately below that line. The part between the brackets [ ] is exactly the same text as what is one the left side of the equal sign in the line above, i.e. InterBase Watcom. You can actually enter any text you want but we are using this for a reason you will see below. The text is the "name" of the driver.
The two lines in the drivers section [InterBase Watcom] describe the file to use for the driver and the setup. Enter the names as shown above.
You can now open the ODBC Administrator in WinOS2 and add a data source. Click the Add button and select the InterBase Watcom driver. Then fill in the setup screen as shown below.
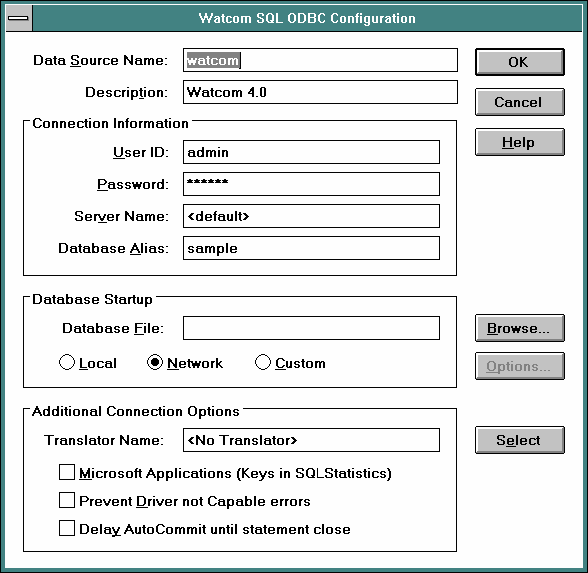
Notice that the values on the setup screen here are the same as they are in the OS/2 driver setup screen - except that the Database Startup radio button is selected for Network instead of Local.
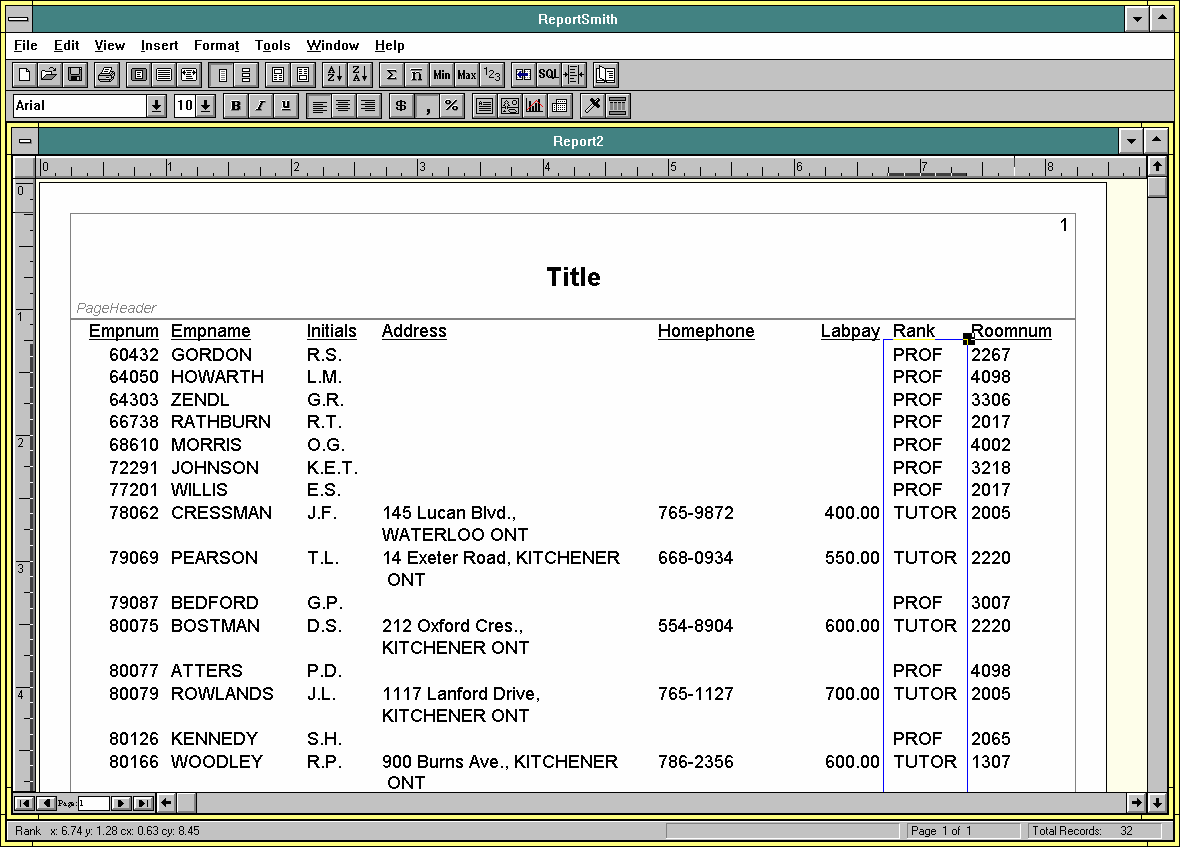
Once you press OK you will have a configured data source for WinOS2 applications. You can access the data from the OS/2 server from WinOS2 applications. The figure below shows ReportSmith displaying a report from the Employee table in the Sample database.
Watcom SQL is an outstanding database. It is fast, has a small footprint, and when you can find it, its cheap. It supports the SQL92 standard very well, has procedures and triggers, referential integrity and WinOS2 support, plus client support for a number of operating systems.
The main user interface to Watcom SQL is an application called ISQL. This is a graphical application where you can enter SQL commands and see the results. It also provides an interface for many of the utilities Watcom has for managing the database and performing administrative functions.
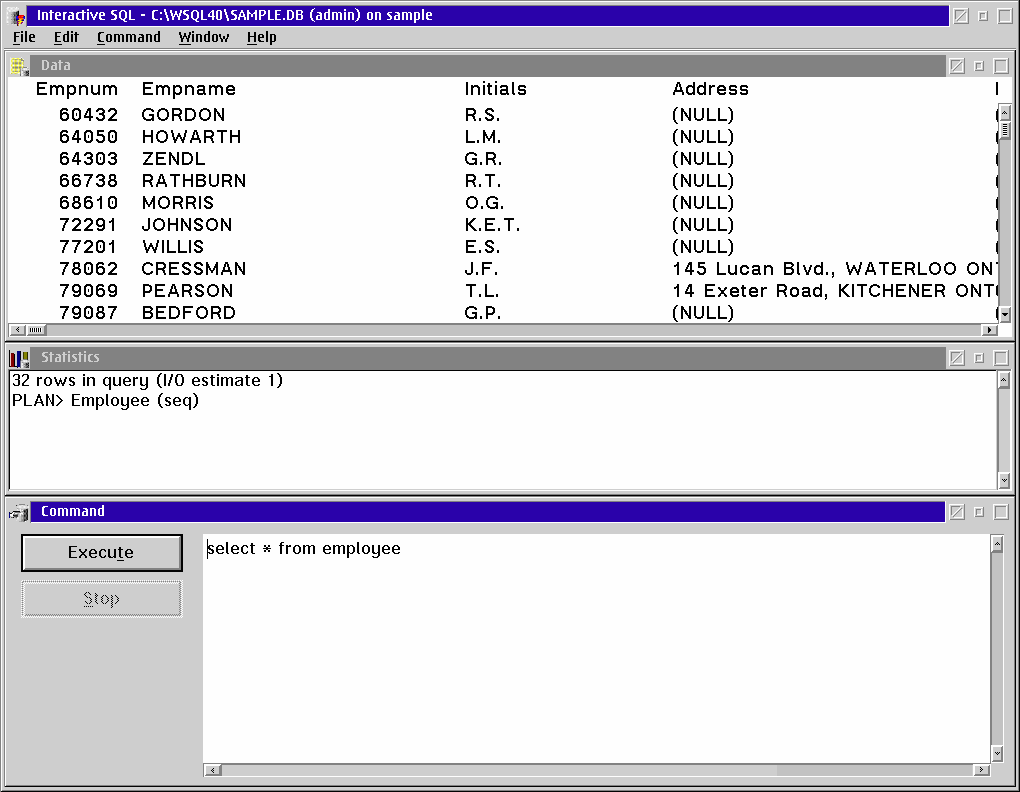
Although Watcom (like some of the other databases we will review) is an older release, it is still very functional for almost anything you would want to do with a database - except connect directly via Java. Most of the functionality of a database is defined by the SQL language standard and what the competition is doing. The SQL92 language standard was approved almost 10 years ago. Once a database is in compliance with SQL92 it has basically reached perfection - not in the sense that there are no bugs or that there isn't anything wrong with the product, but in the sense that it has reached a zenith and further development is just adding features that slow down the database and introduce bugs. Fredric Brooks in the book the "Mythical Man-Month, Essays on Software Engineering" talks about software "wearing out" as a base for progress and needing to be completely redesigned. Further development tends to introduce new bugs and detract from the product until the application is so over developed that it is thrown away and a new product is started. Watcom SQL 4 is almost at the zenith. It complies very well with SQL92, although- not completely, it is fast, and it works. Most commercial databases reached that point roughly somewhere between 1995 and 1998. The open source databases, even the excellent ones like PostgreSQL, are roughly 5 to 7 years behind commercial databases.
The Intersolv drivers can be found in the packages listed above in the ODBC Drivers section
Watcom SQL 4 can occasionally be found on eBay. I purchased by copy for $30 which has a 16 user license, but I have seen them go for as little as $15.
The ODBC Installer is a DrDialog based Rexx program for installing ODBC components. It will install ODBC components for all the ODBC driver and database in all the packages that I know about. The source is included in the package, and there is a way of adding new drivers without modifying the code. It is available at ODBCINST1.ZIP (http://hobbes.nmsu.edu/gi-bin/h-search?key=ODBCINST1.ZIP)
The ODBC Command Processor is a very rough application/tool I built out of desperation. I wanted something to execute ODBC commands to various ODBC data sources and I could not find anything. This is certainly not a production quality release or even a beta level release but it can be handy. I use it every day at my job. It can be had at ODBCCP.ZIP (http://hobbes.nmsu.edu/gi-bin/h-search?key=ODBCCP.ZIP)
ReportSmith is a Windows 3.1 report creation application. In my opinion it is one of the best report making packages available. It is very quick and very powerful. Plus you are working with your actual data when you create the report, so you always see exactly how the report will look. It is somewhat buggy; I have never been able to get the macros to work reliably, but I never really need them either. ReportSmith used to be owned by Borland, but it was sold to some company that still markets a later version. However the best version is the 2.5 one that was bundled in Delphi. You can buy Delphi version 1 or version 2, which includes ReportSmith version 2.5, on eBay regularly for $5. ReportSmith works with a number of data sources but the one of interest to us is the OBDC interface. In order to get the ODBC interface to work however you must perform a very minor hack; you must create names for the database drivers you want to use that begin with "InterBase", just like we did in the Watcom SQL section above.
We have looked at some ODBC drivers and the Watcom SQL database. Next month we will look at more databases, ranging from very big expensive commercial ones to free, open source ones.
This article is courtesy of www.os2ezine.com. You can view it online at http://www.os2ezine.com/20010716/page_7.html.