16 November 2001
Douglas Clark is a program management consultant who first started using OS/2 version 1.3. He's married, with 2 girls, and is old enough to remember when 4 color mainframe terminals were a big thing.
If you have a comment about the content of this article, please feel free to vent in the OS/2 eZine discussion forums.
There is also a Printer Friendly version of this page.
|
Previous Article |
|
Next Article |

ODBC on OS/2 Part 7
In this part we cover IBM's DB2 product for OS/2.
DB2/2
DB2 is the "big guns" database for OS/2, and any other platform for that matter. Of all the databases currently available for OS/2 this database has the best OS/2 support and the best ODBC support. This is true not only for the database itself, but in the sense that DB2 is widely supported by other OS/2 applications, such as Visualizer PE, Sibyl, VxRexx, VisPro, Q+E Database Editor, etc. It is available in configurations ranging from an embedded model intended to be bundled in an application, through a Personal Edition version for one machine one user, to a Workgroup Edition which is the "normal" server handling multiple users on various client platforms, and finally an Enterprise Edition which bundles software for connecting to host (mainframe) based databases.
This database does everything. It is easier to list what it doesn't do than to list what it does. The short answer for OS/2 is it doesn't provide heterogeneous joins across multiple platforms, from version 5 on it doesn't provide Windows 3.1 ODBC access that works, and it doesn't do small: the client application enabler (client software) now takes about 120 MB of disk space. Luckily we can fix the Win16 ODBC problem for version 5-6 as discussed in the section on WinOS2 Support. .
DB2 has a long history on OS/2. It was originally released as an "Extended Edition" package to OS/2 called Database Manager. IBM then released the database under the DB2 name as version 1.x. This version was made from code that was common to the Unix versions and hence was also called "common server". Around 1993-1994 IBM decided to rationalize their database product line across their various operating system and hardware platforms into a "family" of products all carrying the DB2 name. Previously each hardware/software platform had its own database with its own name: AS/400 had SQL/400, VM and VSE had SQL/DS, MVS had DB2, etc. From this point each platform's database was renamed to DB2 and the features and functions started to become similar for each platform. DB2/2 version 2 was released as common server code in 1995. The moniker for the next version of DB2 on OS/2 was changed from Common Server to Universal Database (UDB) and was released as version 5 around 1997. The non-marketing part of the UDB nomenclature indicates the introduction of "object oriented-ness" to the database, in the form of "typed tables" and table hierarchies.
Versions 6 and 7 build on the "object" part of the object/relational features of the database, with few refinements in the SQL capabilities outside of the object aspects. Version 6 also replaces the very nice and reliable C++ based GUI with an all Java GUI - fat, slow, and not very reliable; keeping with the corpulent client trend. Version 7 adds more capability to the object side of the database aligning it closer with Oracle, at least in concept, and for the Windows version adds more integration with Microsoft's version of computing reality.
In what follows we will look at each version, listing some of the more important features introduced with each version along with comments from my experiences using that version. This coverage will in no way be complete but simply a very high level overview; the What's New manual for each version is about 50 pages and I am hoping to make this entire article smaller than that. We will also discuss some topics of interest expressed by readers and caused by new features and directions in the different versions. So in addition to the section on each version there are also sections for:
- General installation issues
- Installing ODBC and ODBC issues
- Cataloguing databases from the client
- NetBIOS problems when installing DB2 on WSeB
- WinOS2 support
- SQL procedures
- Objectness in DB2
- Two phase commits
- Tips on using DB2 without getting a Ph.D. in databaseology
General Installation Issues
The database server can use multiple protocols to communicate with clients. The most common are probably Netbios and TCP/IP. You can pick which protocols you are going to use during the server install phase and it is probably best to just use the default configuration for each protocol.
From version 5 on the help system is HTML based; a small HTTP (web) server is automatically installed which handles search requests and uncompresses the HTML pages before displaying them, etc. You life will be much easier if you make sure your TCP/IP configuration is correct before starting the installation. For instance if you change your IP address after installing the help system it will stop working (there is information in the read.me file describing how to fix that.)
The installation program copies the ODBC files you will need to the install directory, but you need to do something additional to get ODBC working. That additional something is described in the following section.
Installing ODBC and ODBC Issues
DB2 comes with ODBC and everything you need is included: the ODBC Driver Manager, Administrator, and an OS/2 ODBC database driver for DB2. If you do not already have ODBC installed you can click on the Install ODBC icon (version 2) or ODBC Installer icon (version 5 and later) in the DB2 folder to install ODBC after the client (or server) has been installed. Alternately you could use the ODBC Installer and enter the DB2 install directory (normally C:\SQLLIB) as the source directory. In either case the ODBC will be setup on your machine along with the DB2 ODBC driver.
If you already have ODBC installed on your system you don't want to use the Install ODBC icon included with DB2 (you will have to rename or delete some files in your DB2 install directory.) Use instead the ODBC Installer from Hobbes to install the DB2 database driver. This will leave your existing ODBC installation unmolested which is especially important if you have version 3 of ODBC (like what is included in Lotus SmartSuite), since DB2 includes version 2.x of ODBC. If you are not using the DB2 Install ODBC icon you need to rename or delete the following files from the C:\SQLLIB directory: ODBC.DLL, ODBCCP.DLL, ODBCCR.DLL, OS2UTIL.DLL, ODBCINT.DLL. You also will want to rename or delete the file ODBCADM.EXE in C:\SQLLIB\BIN directory.
If you already have ODBC installed you must make sure that the directory containing the ODBC DLLs is after the C:\SQLLIB\DLL entry in the LIBPATH statement of your CONFIG.SYS file. If you don't some parts of DB2 will fail. There is some conflict between something in most ODBC installations and various DB2 components that is fixed by moving the C:\SQLLIB\DLL directory so that its DLLs get loaded first.
Cataloguing Databases from the Client
Cataloguing a database is the process of identifying to the client a database on a remote DB2 server that you want to use. In order to do this you must specify
- the machine address,
- the protocol to use to connect to the DB2 server on that machine,
- the name of the database on the remote server you want to access,
- the name you want to know that database as on your client.
The local name of the database can be the same as the name of the database on the remote server, or it can be different. The reason to make the name different is if you want to connect to two different databases on two different DB2 servers that have the same name, because each cataloged database on your machine must have a unique name. In that instance you would have to catalog one of the databases as a different (local) name in order to be able to access both.
(I keep talking like cataloguing only happens on the client. The truth is that DB2 uses the catalog to access databases whether they are local or remote, so if you are accessing a DB2 database from the server it is also a cataloged database. It is just that when you create a database on a DB2 server it automatically catalogs the database on the server for you so you don't have to perform that additional step.)
In version 2 steps 1-2 are contained in a "node" while steps 3-4 are contained in a "database". So in version 2 you have to first create a "node" where you specify the machine and protocol. Then you define or create databases for that node. From version 5 on the client configuration assistant is simpler and you really don't see the distinction between the "node" and the "database". It is all done with tabbed pages in a notebook. The figures below show cataloguing a database with the version 6 client configuration.
Click on the Client Configuration Assistant icon, then click on the Add button.
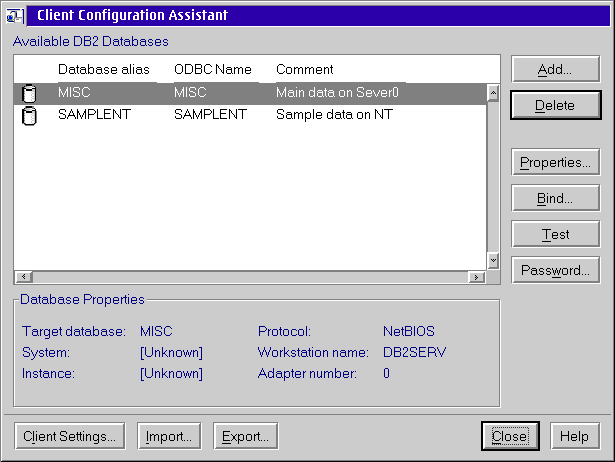
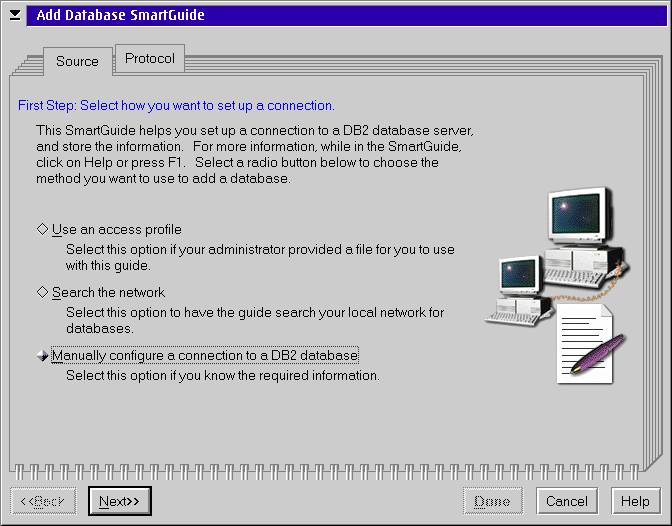
In this example we are going to manually configure the client. The radio button can be used if the database administrator has created a file containing configuration information for you; you would load this file and be done. The second choice has the Client Configuration Assistant going out and searching the network for the server. We don't want to waste our time waiting for the software to find the server, so click Manually configure.
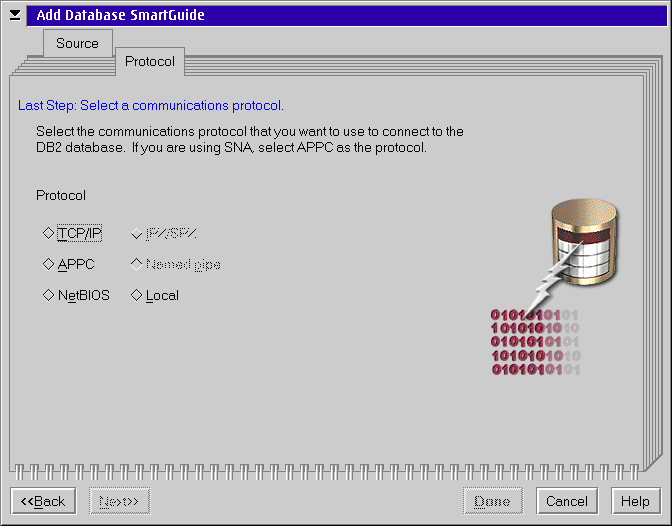
Select a protocol to be used for communicating with the DB2 server. For this example we are going to use TCP/IP. (We show the NetBios page below after finishing the TCP/IP configuration). After you select a protocol additional tabs are added to the dialog for finishing the configuration.
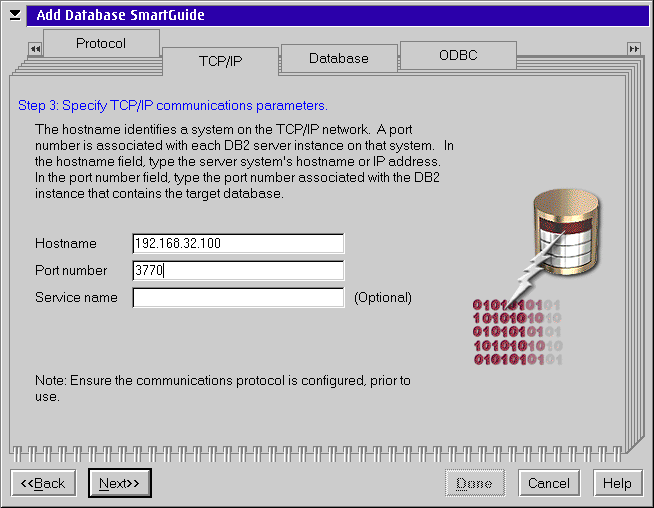
Now specify the DB2 server machine address and port number that DB2 is listening on. The default for version 5 and higher is 50000. We are using a different port number that we picked. No matter what port number you use you must make sure it matches the port number used by the DB2 server. You can specify the hostname as either an IP address or a hostname; in the figure below I am using an IP address.
This page is where you specify the name of the database on the DB2 server you want to access, and what name you want to use for that database. The default is to make both names the same. In the figure below I am cataloguing the database GENERAL as MYDB.
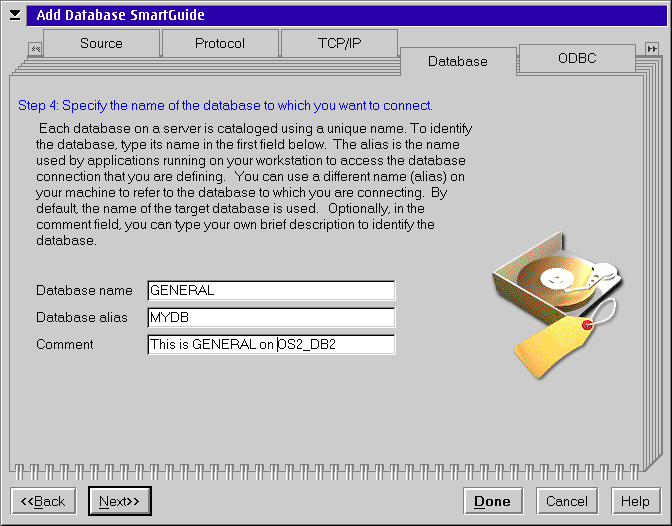
Finally you can have the Client Configuration Assistant add an ODBC data source for this database. Select the check box to have the data source added. Click the DONE button to complete the cataloguing.
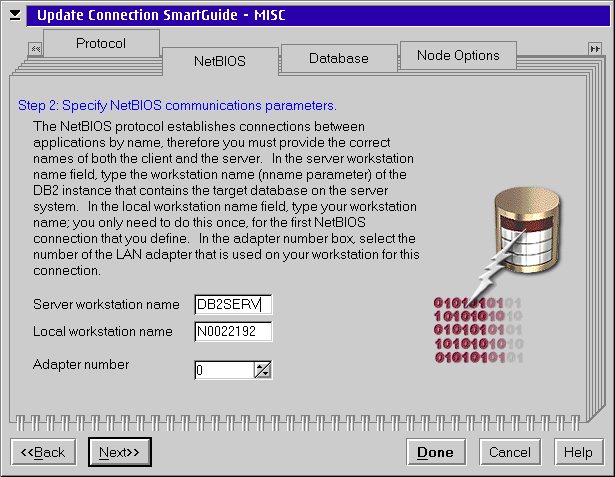
If you chose NetBIOS as the protocol you have to specify a machine address (Workstation name) on this page for the DB2 server. The name used here must match the name specified on the DB2 server.
To find the workstation name used by the DB2 server open the Control Center on the server and right click on the DB2 object. Select Setup Communications from the pop-up menu. Click on the Properties button next to NetBIOS.
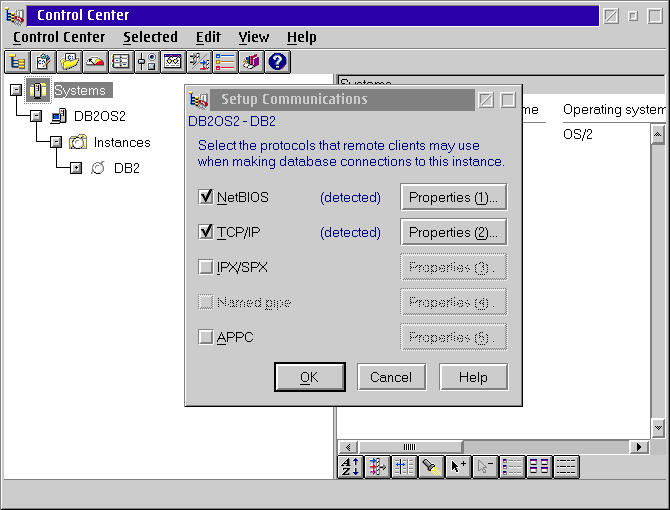
This screen shows you the workstation name used by the DB2 server - in this figure the workstation name is DB2SERV.
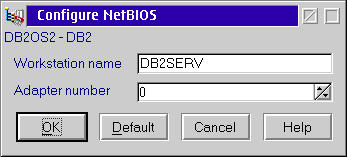
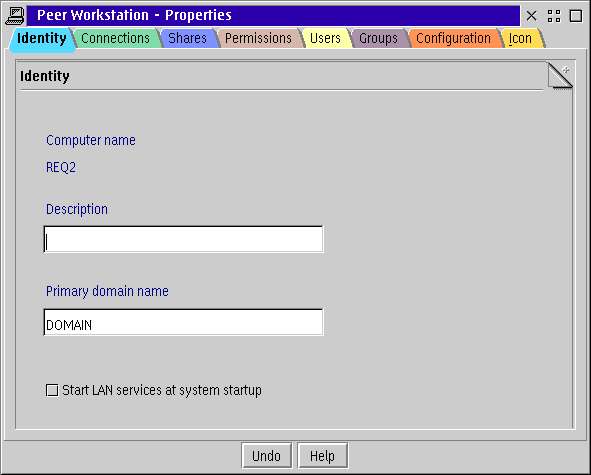
Going back for a moment to the Client Configuration Assistant screen for NetBIOS; there is also a local workstation name on the panel. DB2 automatically picks a name that is (hopefully) unique across the network for your machine. You can leave that name, or you can change the workstation name to match the name used by the LAN client on your machine. That name is visible on the Peer Workstation notebook on the first page.
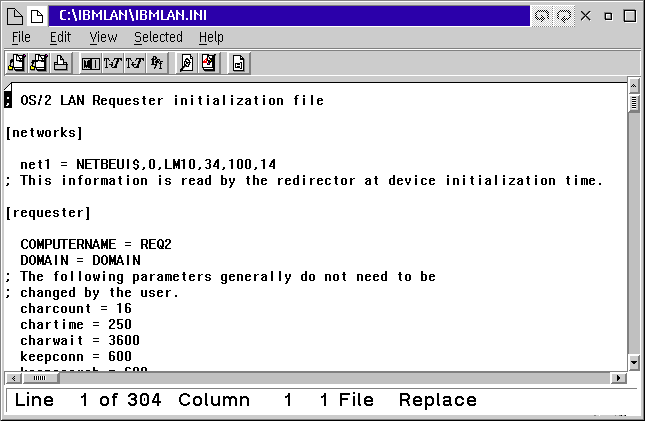
You can also find out (and change) the name is used for you machine by the LAN client in the IBMLAN.INI file, usually located in C:\IBMLAN. The workstation name used by the LAN is the COMPUTERNAME entry in the [requester] section of the file. In the figure below my workstation name is REQ2.
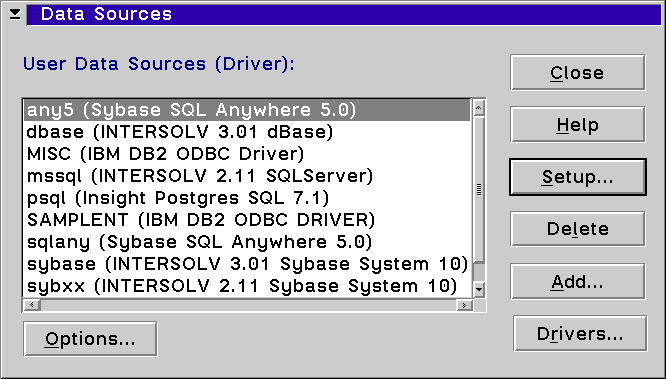
If you chose to not have the Client Configuration Assistant add the ODBC data source for this database, or if you need to re-add it manually you can do that from the ODBC Administrator. Open the ODBC Administrator and click on the Add button. Then select the IBM DB2 driver and click OK. You will be prompted to select a cataloged database from a drop down list.
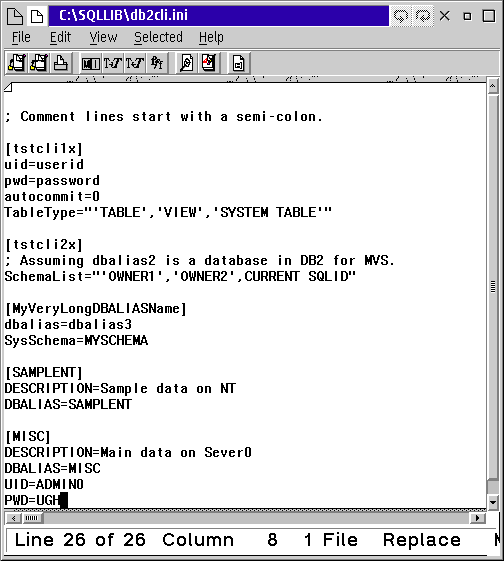
The file DB2CLI.INI in the C:\SQLLIB directory contains an entry for each database cataloged on your machine. You can edit that file and add a default user ID and password to be used for connecting to each cataloged database. Each cataloged database is in its own section identified by the database name in brackets. Add a line for UID= to specify the user ID, and a line starting with PWD= to specify a password. Then when you connect to that database if you do not specify a user ID and password the ones specified in the DB2CLI.INI file will be used.
NetBIOS Problems in WSeB
For big installations the DB2 server is normally installed on its own machine. For my small network (6 machines) I installed DB2 Server in my WSeB machine - I didn't have enough traffic (and money) to justify a separate machine for the database server. When I installed DB2 the NetBIOS communication would not start up, it always generated an error while the other protocols started correctly.
The problem is that DB2 and WSeB are both a using NetBIOS resources from a finite pool available resources. To fix the problem I had to go in and reduce the number of NetBIOS resources gobbled up by WSeB. I initially tried to do this by adjusting NetBIOS parameters from MPTS, and by manually editing the PROTOCOL.INI file. Neither method fixed the problem. But when I used the Warp Server Tuning Assistant (located in the LAN Services folder) to adjust the projected number of LAN clients I managed to make the problem go away. It appears that the default configuration for WSeB is for so many clients and sessions that it uses enough NetBIOS names to prevent DB2 from getting the number of names it wanted.
Why you ask, would anyone in this internet-connected world want to use NetBIOS anymore? I can think of potentially three reasons:
- NetBIOS is faster than TCP/IP. Or at least it used to be. Back around 1994 Data Communications magazine commissioned Tolley Laboratories (a testing lab) to test various TCP/IP implementations from various manufacturers on various operating systems. The lab was surprised to find that IBM's TCP/IP implementation was the fastest of those tested, and that NetBIOS was substantially faster than TCP/IP. I don't know if that is still true.
- Performance between a web server and database server. You can configure an OS/2 machine with up to 4 network adapter cards. I believe that you can bind specific protocols to adapter cards (although I never got around to actually testing this.) If you have an installation where a web server interacts frequently with a database server, say you have lots of CGI programs that retrieve data from a DB2 server, you could add an additional network card to the web server and database server and route communications between the two on their own private network - NetBIOS. And if you are connecting just two adapter cards together you don't even need a hub.
- NetBIOS for the database communications allows the database to still be accessible when someone is using the PPP dialer on the database server, which disables "normal" LAN TCP/IP communications. (My server is fully utilized)
WinOS2 Support
In my experience the Windows 3.1 client for DB2/2 version 2 works very well, especially for Windows ODBC applications. Starting with version 5 of DB2 the Windows 3.1 client was not included in the distribution, you had to download it from the web. Which is OK because it doesn't work very well, at least with the applications I use. It appears that the client is a little bit piggy and takes up too much stack space. Version 5 was also the last DB2 client released for Windows 3.1.
The solution is the use the version 2 Windows 3.1 client, which works fine for DB2/2 versions 2, 5 and 6. Starting with version 7 there is a new restriction on CAE software connecting to different versions of server; the restriction is that a client enabler application can only connect to a server 2 versions higher, and one version lower. This means that a version 5 client can connect to a version 7 server (within 2 two version limit), but a version 7 client cannot connect to a version 5 server (more than 1 version back.) I assume this restriction applies to the Windows 3.1 client, but I have not tested it; I have tried connecting to a version 5 server with a version 7 client and it won't work. So what that appears to mean is that if you want to still use your WinOS2 applications don't buy version 7 of the server; pick up version 5 or 6 of the server instead. Normally this version restriction for the clients is no big deal because IBM freely posts the DB2 clients on their web site - you can go there and download whatever client you need. (IBM charges by the number of connected users just like everyone else. But everyone else does not post their clients and it can be a pain to try and find a client that will work with other vendors. Thank you IBM for being so rational.) But for WinOS2 applications this restriction is a big deal, since IBM has withdrawn the version 2 CAE packages from their web site. So you have to go to Hobbes to download the version 2 Windows 3.1 CAE.
There are two ways of installing version 3 Windows 3.1 CAE: one is for installing in WinOS2, and one for "regular" Windows 3.1. If you are running the version 2 OS/2 CAE then you want to install for WinOS2. This Windows 3.1 CAE shares files with the OS/2 client, including sharing a common catalog so that when you catalog a database on OS/2 it automatically shows up in WinOS2. If you are running a version 5 or version 6 OS/2 CAE then you want to install the "regular" Windows 3.1 client. The difference between the two is that when installing for WinOS2 you specify the same directory for the Windows client as is used for the OS/2 client. When installing for the "regular" client you do not use the same directory as the OS/2 client. It you try and install the Windows 3.1 client in the same directory as an OS/2 version 5 or version 6 client you will get an error message on the install that the clients are incompatible.
The installation is pretty straightforward. Unzip the file WIN31CAE.zip into a temporary directory. Execute the file x:\tempdir\windows\en\client\install.exe - where x:\tempdir is the directory where you unzipped the file. For version 5 and 6 OS/2 clients be sure to pick a different directory for the Windows 3.1 client from the one where the OS/2 client is installed; they cannot both be installed in the same place.
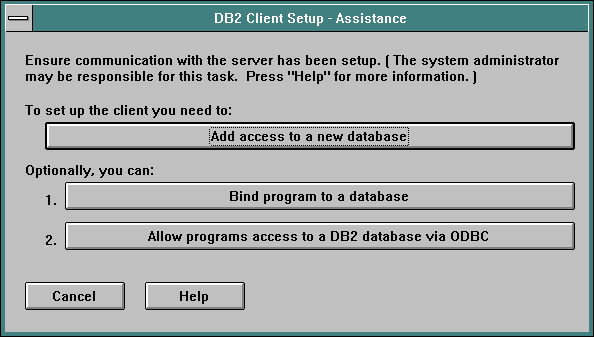
Once you have installed the client and restarted WinOS2 you have to catalog a database. Start the Client Setup program. The first time the Client Setup program runs you are presented with a "wizard like" series of dialog screens. The first screen is shown below - click the Add access to a new database button.
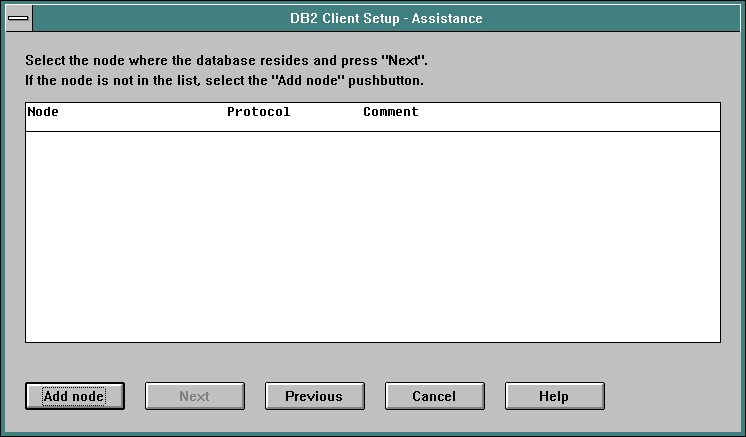
Then click the Add node button.
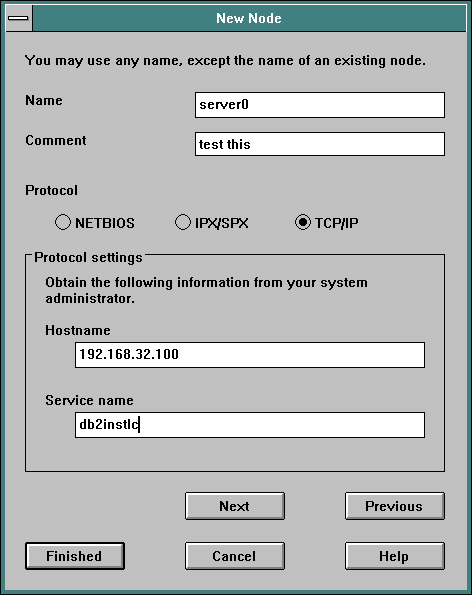
Now select enter a name for the node. Any name will do, maximum of 8 characters. Select a protocol, we will use TCP/IP in this example; NetBIOS is a little more complicated and is covered below. Enter a host name or IP address and service name.
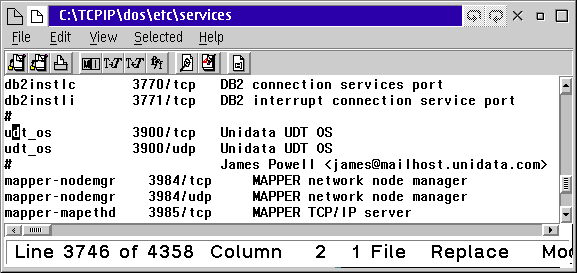
On this screen you must enter a service name rather than a port number. That service name must appear in your c:\tcpip\dos\etc\services file, and in the services file on the DB2 server you are connecting to. The services file on the DB2 server is probably in C:\MPTN\ETC directory. This figure shows the entry for the service name in the c:\tcpip\dos\etc\services file. Notice that there are two entries required: one that matches the service name listed on the node screen, and one that is one number higher. In our case we are using the service name db2instlc with the port number of 3770, so we also require an entry in the services file for port number 3771. (The one-number-higher port is used for interrupts.)
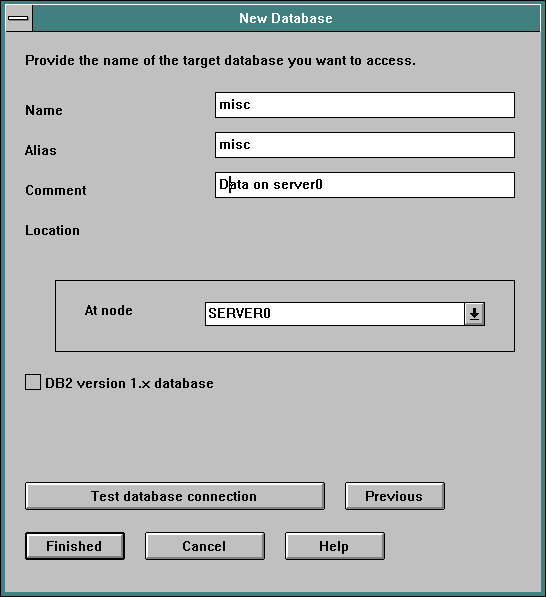
Now you have to specify the database. The Name entry equals the name of the database on the DB2 server. The Alias entry is the name you want to use on your machine for that database; we are using the same name for both here.
Press the Test database connection button to see if everything is working correctly. You will be presented with a logon screen where you enter the user ID and password for the database. If the connection is working correctly you will get a message, or an error message if something is wrong.
You can create additional nodes without the wizard helper screen stuff by selecting New from the Node menu. Or you can alter the settings for an existing node from the Node - Open as - Settings. You can also add additional databases for one or more nodes by selecting the node and pressing the Databases button.
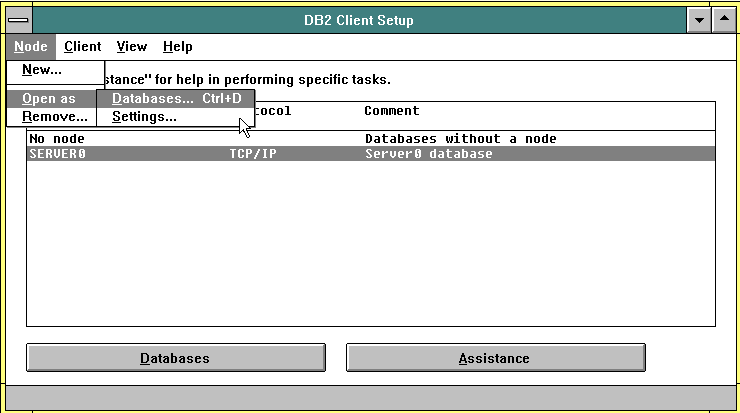
When I tried to add a node on an eComStation machine that used NetBIOS to communicate with the server I discovered the node wouldn't work. After about 3 hours of trouble shooting and reading up old books on OS/2 and DOS LAN networking I came to the conclusion: it doesn't work eComStation and WSeB installations. It does work on Warp 4 machines. Which unfortunately reflects a general trend with WSeB and eComStation for screwing up WinOS2. Programs that work great in WinOS2 on Warp 4 don't work at all, or don't work very well on eComStation and WSeB. Whatever IBM did to WinOS2 in that release I sure wish they would undo. I have some Windows 3.1 programs that I use regularly that I don't want to upgrade, or I can't upgrade and still run on OS/2: FrameMaker 3, Acrobat 3, ReportSmith 2.5 and Improv to mention 4.
NetBIOS details: Since DOS, and therefore WinOS2 sessions, run in a virtual machine in OS/2 IBM needed some way of virtualizing the networking services for DOS/WinOS2 programs. OS/2 uses the virtual 8086 (V86) feature of the 386 (and higher) CPU which separates V86 programs from other programs that are running; to each DOS session it appears as if it is running on its own machine. The way OS/2 does this is to install a virtual device driver that intercepts DOS networking calls and routes that call in ring 0 to the OS/2 device driver. Warp 4 automatically installs the 2 device drivers needed for DOS NetBIOS networking: c:\ibmcom\protocol\lanvdd.os2 and c:\ibmcom\protocol\lanpdd.os2.
This is a diagram of how this works.
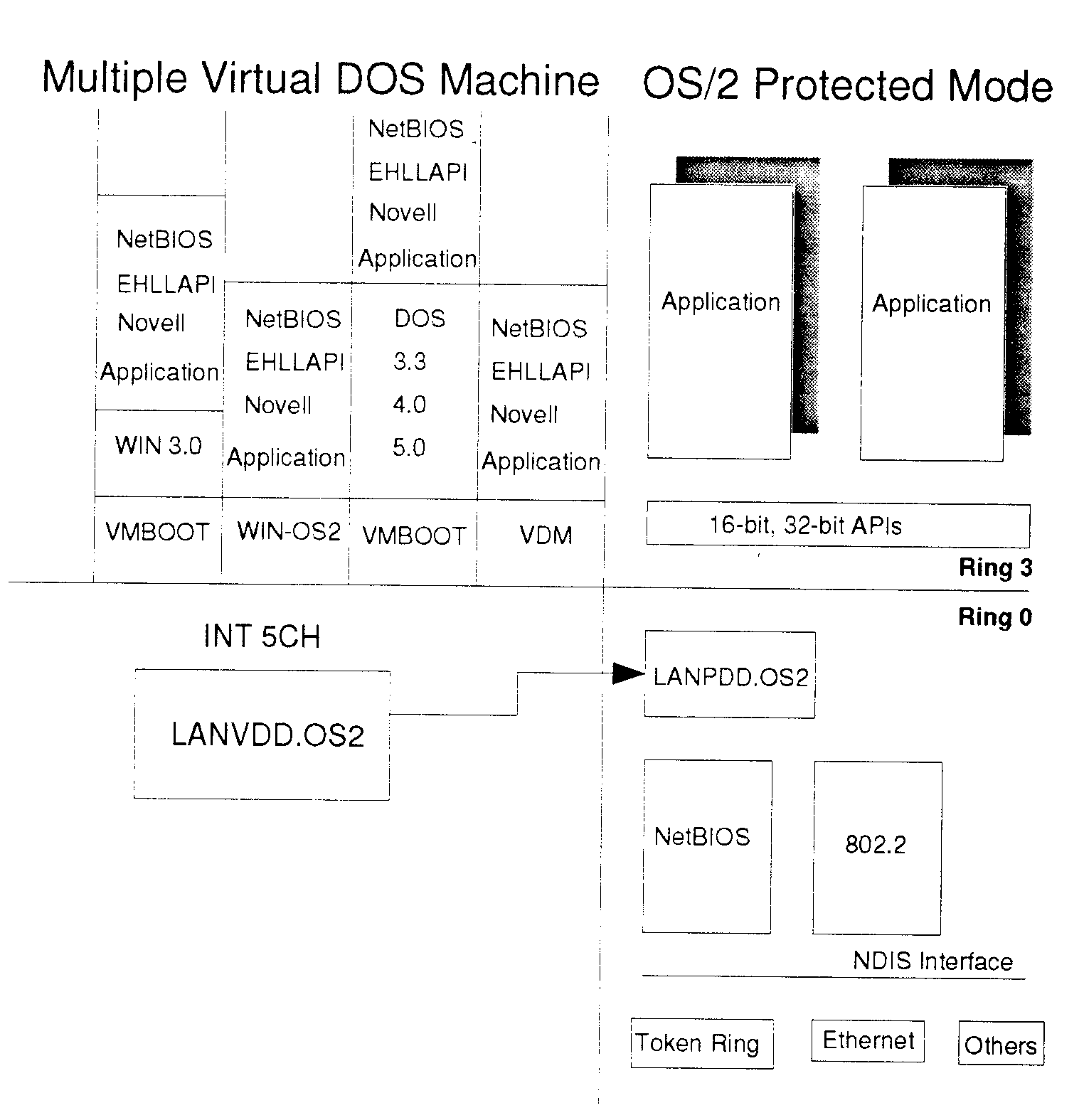
For some reason eComStation and WSeB don't install those device drivers in the CONFIG.SYS file. However when I manually put the device drivers in my CONFIG.SYS file I still couldn't get the NetBIOS service to work in DOS/WinOS2. One of the drivers is slightly different in size on the eComStation distribution than on Warp 4, but moving the files over from Warp 4 still didn't work. So the conclusion seems to be that if you want to use NetBIOS DOS or Windows 3.1 programs stay with Warp 4. (Actually if you use a lot of WinOS2 programs of any type you may want to stay with Warp 4.) Fortunately TCP/IP support for DOS still works in eComStation.
Version 2
This version is rock solid. It is very very reliable and trouble free. The CAE (client software) size is a reasonable 12-18 MB on OS/2. The Win16 ODBC part works correctly. My biggest complaints for this version are: 1) no outer join in SQL, 2) setting up clients is less than intuitive, 3) the graphical administrator tools aren't nearly as nice as what is provided in version 5. The lack of outer joins in SQL is the most annoying of the problems but it can be worked around in SQL statements.
Version 2 includes for the first time ODBC support, the ODBC Driver Manager and Administrator are bundled in DB2/2 along with a database driver for both OS/2.
In order to provide large table support, and for performance reasons, something called database partitioning appears for the first time. The performance implications are best explained by quoting from the version 2 Planning Guide.
Database administrators can partition a database into parts called table spaces . A table space has one or more containers associated with it. Containers are separate identifiers of storage space to be used by the table space. A container is either a system file or a directory.
When creating a table, you can have indexes and large object data kept separate from the rest of the table data. These separate table spaces can possibly be on different media than the rest of the data. This flexibility can be used to increase database performance and availability.
Indexes stored in a different table space from that used to store other table data can allow for more efficient use of DASD (hard drives) devices by reducing the movement of the read/write heads. You can also allocate faster devices to indexes which can speed index access.
Long column data (LOBs) stored in a different table space can allow you to allocate a special device for this type of data. For example, you may choose to store large object data on devices that have very large capacity, but may be slow, while the rest of your data that may be accessed more often, can reside on a faster device.
By splitting data across devices, the prefetch operations become more effective at improving performance....
New containers can be added with an alter tablespace command on the fly. The database manager will then automatically re-balance the tables in the table space across all available containers. During rebalancing, data in the table space remains accessible.
Since the most costly single component of database access is hard disk access, it can pay large performance dividends to optimize the database structure. This can range from something as simple as using three hard drives in a database server (one for the operating system files and swap file, one for the database tables, one for the log files) to more elaborate structuring described above.
Enhancements
- Ability to split the database (tables) across multiple partitions.
- Limited JDBC connectivity. This came out after the initial release of version 2.
- Triggers.
- Two phase commit - when accessing other DB2 databases via DDCS (an add-on product.)
- Large Object(LOB/BLOB) support. Large Objects can be up to 2 GB in size; previously the largest data size that could be stored was 2000 characters in VARCHAR field.
- User defined functions.
- User defined data types.
User defined types are something like typedefs in C: they are a datatype that is based on one of the built-in types but which you want to treat as a different type. For instance you might what to create user types of picture and audio, both of which would be based on BLOB type. The advantage of defining a new type for an existing built-in type is that you can control which functions and comparisons are appropriate: for example it would not be appropriate to compare (=) an audio type to a picture type.
User defined functions are scalar type functions that you can create with C, C++, COBOL or FORTRAN and then use in SQL statements just like built-in functions. When you define the user function you specify the data type of the input parameter(s), thereby controlling which datatypes are appropriate for use in the function. User functions can also be overloaded, i.e. multiple functions with the same name but different input parameter types can be defined.
SQL Enhancements
- Check constraints
- Case expression
- Scalar fullselect expressions
- Nested table expressions
- Distinct subselect.
- Count column function
- Cast for changing the type of a returned value.
- Recursive queries
Installing and Using
There are no special instructions for installing this version, just follow the instructions in the install program. It is fairly simple.
When you install version 2 you end up with a folder that looks like this.
You will also end up with a folder in WinOS2 that looks like this. The catalog is unified between WinOS2 and OS2, meaning that when you catalog a database in OS/2 that database shows up in the WinOS2 catalog automatically and is available to WinOS2 applications immediately.
The administrator functions are handled through the Database Director. The figure shows the pop-up menu for a database with the options for working with a database. The Database Director can administer both local and remote databases. In this figure are shown local databases and remote databases.
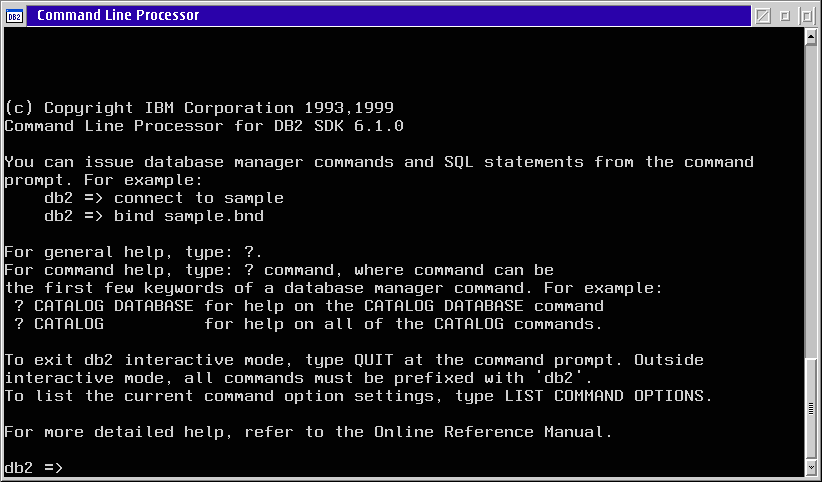
The only tools included for working with the database, other than the Database Director, is the Command Processor. This is a text based window that accepts and processes SQL and DB2 configuration/administration commands.
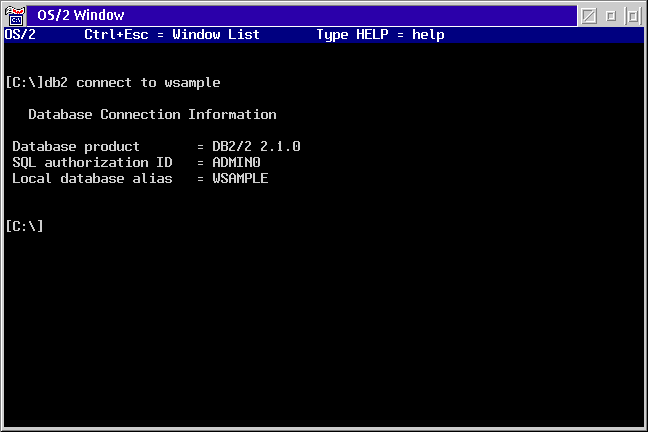
A variation on the Command Processor is using the DB2 command from any OS2 Command Prompt. You enter DB2 followed by any command you can use in the command processor. This makes it easy to interweave DB2 and shell commands.
Version 5
Commercial versions of 5.0 were included IBM's Visual Basic. IBM's official position was that basic was going to replace Rexx as the cross platform scripting language of choice. Version 5 has provisions for creating procedures and user defined functions in basic. IBM's Visual Basic was such a commercial disaster that Visual Basic was shortly thereafter unbundled from DB2/2 and withdrawn from the market.
Enhancements
- Java is supported for creating user defined functions and stored procedures.
- Support for system memory greater than 4 GB.
- Governor facility added for reprioritizing or terminating a query that exceeds resource limits.
- Significantly improved CAE configuration.
- New generate_unique function for creating unique values on insert.
- Maximum number of columns in a table increased to 500.
- CLI interface updated to ODBC version 3 specification. The OS/2 ODBC driver is still at version 2.x.
- Various performance enhancements for query processing.
- Documentation is in HTML instead of INF format. Requires a mini-HTTP server for serving the help pages along with a search engine. The advantage is searching is more powerful and cutting and pasting is easier. The disadvantage is it is much slower.
SQL Enhancements
- Outer join
- column level update authorizations
- rename table and column
- cube and rollup aggregations
Installing and Using
Don't install the version 5 Windows 3.1 client, use the version 2 Windows client.
Once you have installed version 5 you will have this folder on your desktop.
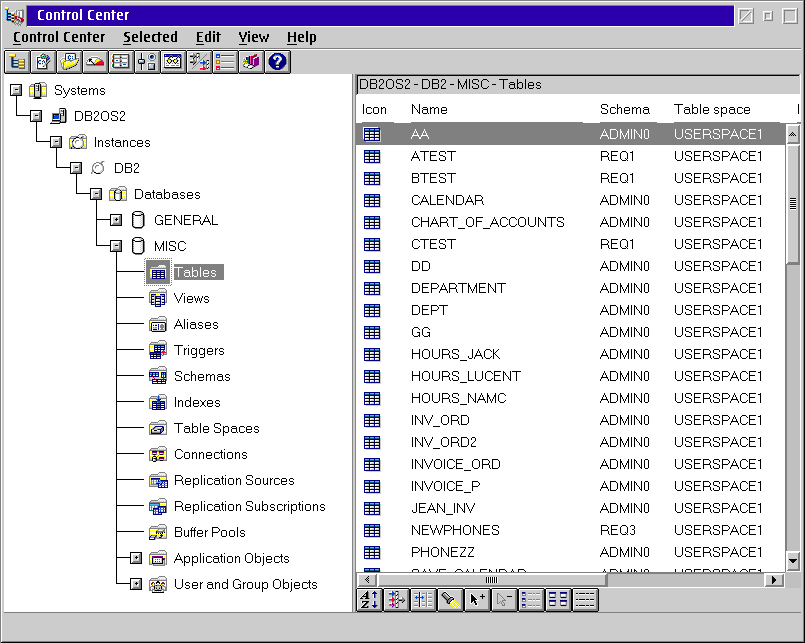
Administration functions are handled with the Control Center.
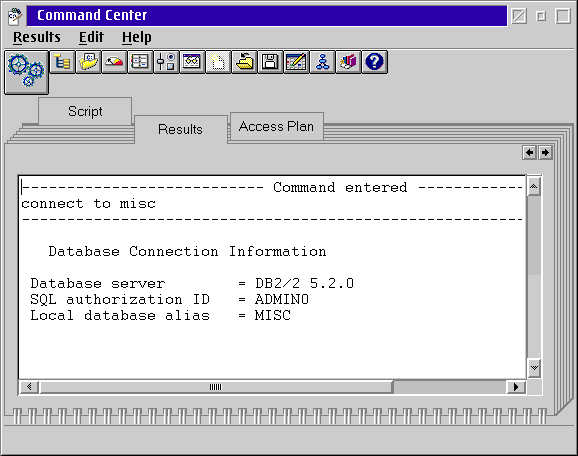
In addition to the text based Command Processor there is a graphical Command Center.
This is my favorite version of DB2. It has many of the SQL enhancements I want and is reliable. The GUI tools are not Java and perform reliably and quickly, which is not true for version 6. Even though I have access to versions 2 through 7 this is the version I have installed on my server.
Version 6
This is not the most reliable version DB2 ever released. I upgraded the server of one of my clients from version 2 to version 6 and we almost reverted to back to version 2. It started with the install, where we ran into a problem and called IBM for support. IBM wanted $1700 to help us with our install problem - which was more that what my client paid for the upgrade. (Could I have the old IBM back - the one with the reputation for outstanding service?) The problem turned out to be some incompatibility with DLLs in the ODBC directory and DB2 DLLs. Then we found out that we could not use the GUI to restore a database; the GUI issued an incorrect call to DB2 and the restore failed. We got around that by using the Command Processor to enter the restore command. A table in the database became corrupt twice, necessitating that the table be deleted and recreated from backups. The new and improved Load utility leaves the table being loaded in a weird twilight state if the Load fails. When we created scheduled backup "jobs" those jobs became permanent and we could never delete the jobs; they continue to try and run to this day. (I guess we could pay IBM $1700 to tell us how to get rid of the jobs.) And the list goes on. Compare this to version 2 which I have never had any problems with.
SQL Enhancements
- Table name length increased from 18 characters to 128. Column name length increased from 18 characters to 30 characters.
- The size of a single SQL statement is increased to 64K.
Other Enhancements
- Scrollable cursors are introduced for ODBC and CLI programs
- Data storage page sizes are now: 4K, 8K, 16K and 32K. The larger page sizes allow individual data rows of up to 32,677 bytes, and up to 1012 columns in a single table.
- Index key length is up to 1024 bytes.
- Various object oriented features are enhanced or added.
Version 6 is where multiple features and additional products start to appear for Windows that are not released for OS/2.
Version 7
I can't speak very much from personal experience on version 7. I installed it on a laptop I borrowed for Warpstock and could not get any of the GUI applications to work - although the database would start and stop. So this stuff is strictly from the manuals.
Enhancements
- XML features - XML statements can be stored as their own column type, or they can be decomposed and stored as parts in columns in multiple tables.
- A new SQL procedural language now is available for writing stored procedures. Plus stored procedures can now be nested, i.e. one procedure can "call" another procedure.
- Temporary tables are now supported.
- OO features are brought more in line with Oracle's implementation. "Structure types" can now be used to define columns instead of just tables. In addition structures can now be nested within other structures.
- Methods can now be defined, "which permit the encapsulation of behavior with data. A method is defined very much like a function, but its use is strictly associated with structured types. It is essentially a routine with a structured type instance as its implicit first argument." Sounds something like the scheme that SOM used to turn procedural language (C) functions into class methods.
SQL Procedures
New in version 7 is SQL Procedures, a language for writing SQL stored procedures in a procedural language that is something like Oracle's PL*SQL.
You create procedures with a create procedure command from the DB2 Command Processor. And just like Oracle, debugging a procedure can be something of a pain, although it looks like debugging DB2 procedures is more difficult. DB2 can accept the syntax of the procedure and still fail to create the procedure in a couple of different stages. You have to look at the SQLSTATE return from the create procedure command to see if the syntax of the procedure was rejected, then you have to check an error message log to see of the procedure was rejected even though the syntax passed. There are also intermediate files that can be looked at to help in debugging.
SQL Procedure statements are described below, quoted from DB2 version 7 Application Development Guide.
Valid SQL Procedure Body Statements
A procedure body consists of a single SQL procedure statement. The types of statements that you can use in a procedure body include:
Assignment statement
Assigns a value to an output parameter or to an SQL variable, which is a variable that is defined and used only within a procedure body. You cannot assign values to IN parameters.
CASE statement
Selects an execution path based on the evaluation of one or more conditions. This statement is similar to the CASE expression described in the SQL Reference.
FOR statement
Executes a statement or group of statements for each row of a table.
GET DIAGNOSTICS statement
The GET DIAGNOSTICS statement returns information about the previous SQL statement.
GOTO statement
Transfers program control to a user-defined label within an SQL routine.
IF statement
Selects an execution path based on the evaluation of a condition.
ITERATE statement
Passes the flow of control to a labelled block or loop.
LEAVE statement
Transfers program control out of a loop or block of code.
LOOP statement
Executes a statement or group of statements multiple times.
REPEAT statement
Executes a statement or group of statements until a search condition is true.
RESIGNAL statement
The RESIGNAL statement is used within a condition handler to resignal an error or warning condition. It causes an error or warning to be returned with the specified SQLSTATE, along with optional message text.
RETURN statement
Returns control from the SQL procedure to the caller. You can also return an integer value to the caller.
SIGNAL statement
The SIGNAL statement is used to signal an error or warning condition. It causes an error or warning to be returned with the specified SQLSTATE, along with optional message text.
SQL statement
The SQL procedure body can contain most, but not all, SQL statements that are generally allowed in procedures.
WHILE statement
Repeats the execution of a statement or group of statements while a specified condition is true. Compound statement Can contain one or more of any of the other types of statements in this list, as well as SQL variable declarations, condition handlers, or cursor declarations.
Example SQL Procedure
CREATE PROCEDURE UPDATE_SALARY_IF
(IN employee_number CHAR(6), IN rating SMALLINT)
LANGUAGE SQL
BEGIN
DECLARE not_found CONDITION FOR SQLSTATE '02000';
DECLARE EXIT HANDLER FOR not_found
SIGNAL SQLSTATE '20000' SET MESSAGE_TEXT = 'Employee not found';
IF (rating = 1)
THEN UPDATE employee
SET salary = salary * 1.10, bonus = 1000
WHERE empno = employee_number;
ELSEIF (rating = 2)
THEN UPDATE employee
SET salary = salary * 1.05, bonus = 500
WHERE empno = employee_number;
ELSE UPDATE employee
SET salary = salary * 1.03, bonus = 0
WHERE empno = employee_number;
END IF;
END
@
Objectness in DB2
Object oriented features have been making their appearance in DB2 since version 2. When User Defined Functions and User Defined Types made their debut in version 2 they were billed as introducing object oriented features into the database. With each release there have been more and more features added for object part of the object/relational functionality. Apparently Oracle's implementation is driving the feature set of DB2. We discussed object/relational features some in a previous article but we will cover some more here.
For clarity of discussion I think we should define two uses of the term "objects" in databases:
- Object oriented meaning anything that is not relational and includes some kind of hierarchy.
- Object oriented meaning the ability to use the database to provide persistence for objects used in applications or other programs.
Lets take #1 first. This is what the database vendors mean by the object part of object/relational. Hierarchical databases existed before relational databases did. Relational technology and theory was developed as a method for storing data and retrieving data with some kind of standardize language. The idea behind SQL was that the language was simple enough that the average user could use it to retrieve data, i.e. the user of the data could retrieve what he needed rather than having to wait for a programmer to create a retrieval program for him. SQL is based on some relational concepts, the most famous being Dr. Codd's relational rules. Objects, by definition being beyond relational, do not fit the relational model. They break many of relational rules that SQL is based on. So not only do new "data types" have to be defined, but a new language for addressing those data types. This is so contrary to traditional relational concepts that transformations have to be done on these new object types in order to get them in and out of the database; version 7 introduces transformation functions for doing just that.
Will objects in a object/relational database ever be just like programing language objects, meaning will they have data and methods encapsulated together? That seems to be the direction and intent of IBM. Version 7 introduces new "methods" for attaching functions or procedures to data to mimic objects. (What the new "methods" appear to really do is associate a function with a "data structure type" which is just a refinement of the User Defined Function that has existed since version 2.) If this is taken to its logical conclusion it seems that the database becomes a programming language, albeit a very clunky one. Since the purpose of methods in objects is to that the object can respond to "messages" sent to it, then objects in DB2 compete with object oriented languages.
Consider C++, SmallTalk and Object Rexx which are all object oriented languages. The languages are structured around objects. Data and functions (methods) wrapped up together into an object along with some kind of hierarchy where lower level objects `inherit" data and methods from higher level objects forms the basis of those (and all other) object oriented languages. These languages are all designed with extensive procedural programming power available for working on and inside of objects, which DB2 does not have. DB2's methods for working with objects are all (except for the new SQL Procedural Language) written in some other language - like C or C++ or Java, etc. But DB2 makes the objects persistent.
Now definition #2 - Object oriented meaning the ability to use the database to provide persistence to objects used in applications or other programs. The problem with all these object oriented languages is that the objects are not persistent: when the program stops running the objects disappear. In some areas this ends up being a big problem for object oriented languages. Lets make up an example to see why persistent is important. Say we created a report building application what was designed to be object oriented and that used C++. The report builder uses page objects to represent pages in the report and to handle page oriented features like page size, margins, orientation, etc. The report builder also uses column objects to represent columns of data: each column has "attributes" (data) that store the width, font, etc. A user creates a report by dragging a page object to a palette and dropping column objects on the page object, adjusting the column widths and fonts, etc. When the user is done composing a report we need to save what he has built so that the next time he runs the report it is all there. This is where object persistence comes in. If we had object persistence we could just save off the page object the user created along with all the column objects that belong to the page(s). Since we are using C++ however there is no object persistence. Therefor we have to figure out some way of saving information about the objects so that the next time the program runs we can recreate the objects from scratch making sure that the new objects we create match what was "saved".
You would think that here is where object/relational databases come in to save the day. Except the database is not offering to store our C++ generated objects. Instead the database is offering for us to create our objects in the database instead of in C++, and to create procedures/functions to act as the object's methods. So in essence the database is trying to replace the language. But while the database is very good at storing stuff, it is terrible at handling functions; remember that SQL is by definition non-procedural, and programming languages are all procedural.
Storing objects created outside of the database in some external language is a very different problem from storing objects created inside the database, especially if the storage process is not to cripple in some way features of the object oriented language. IBM Systems Journal published an article in 1996 (volume 35 number 2) titled Storing and Using Objects in a Relational Database describing a software package called Shared Memory-Resident Cache (SMRC) that did just that and described some of the problems of storing language objects in a relational database. (The SMRC stored objects in the BOLB field(s) of normal tables.) The problems are related to storing the memory pointers of the objects in the database and then restoring those pointers correctly back into memory when the objects where reloaded. The article referred to this process of converting database stored pointers into main memory address pointers and the relocation of those pointers as swizzling - they were saving and restoring C++ language objects. Plus the complexity becomes much greater when the object is stored off of one operating system and restored to another which is necessary to keep the database and its clients from becoming tied to one operating system.
The bridge between language created objects and database stored objects is not included in the DB2 or Oracle object/relational models, although some third party vendors have made some products to do just that, including the Shared Memory-resident Cache described in the article above - but all of those store the objects in the relational part of the database. Where object features in a relational database are going is anyone's guess, but I am confident that it will take quite a few years to get there.
Two Phase Commits
Distributed transactions, or two phase commits, have been a part of DB2 since version 2. Distributed transactions mean a single transaction consisting of at least 2 SQL statements, each of which address a different database. This is different from heterogeneous database access which means a single SQL statement that references tables on different databases. That function is provided by what DB2 called Federated Systems or by DataJoiner.
The complexities of two phase commits was covered in a previous article so we will just address some of the mechanics as relates to DB2 here. In order for two phase commits to work there must be some "transaction monitor" that keeps track of what is happening in the transaction, and that is responsible for restarting the transaction if one of the databases fails. DB2 provides its own transaction monitor for distributed transactions that are against only DB2 databases. DB2 can also work with certain external transaction monitors when the distributed transaction references non DB2 databases. When using the DB2 transaction monitor an application has to make a different "type" of connection, called a type 2 connection by DB2.
Running DB2 without having a Ph.D.
DB2 is a very big and complex database. But there are things you can configure in order to run with a minimum of care and feeding. Here are two tips for minimizing administration:
- Turn off logging. Log files are created by the database and store details of transactions so that the database can be rolled forward to a point of failure if something bad happens to the database. We are talking power or disk failure here rather than accidental deletion of data. The problems with log files are: they take up space, sometimes lots of space, you have to save the log files with the backups, and restore the log files with the backup or have them present somehow. If you disable logging (or rather change logging to be circular) then you can only restore to the last backup that you took. If you sustain a failure between backups you can only get data from the last backup. But you don't have to worry about running out of space, or accidentally deleting a log file you needed when trimming log files.
- Use operating system files, rather than database specific partitions, for table spaces. If you use database specific partitions you have to be concerned about running out of space and resizes partitions. With operating systems partitions resizing happens automatically, up to the size of the disk partition.
Conclusion
DB2 is an excellent database, with very complete support for ODBC on OS/2 and WinOS2. All the versions from 2 through 7 are good databases, and you can pick up some of the other versions for very cheap.
Next month we start talking about how to program in ODBC. We will cover (although not all next month) writing programs in C, C++ Rexx and Sybil, all of which can access ODBC enabled databases.
|
Previous Article |
|
Next Article |